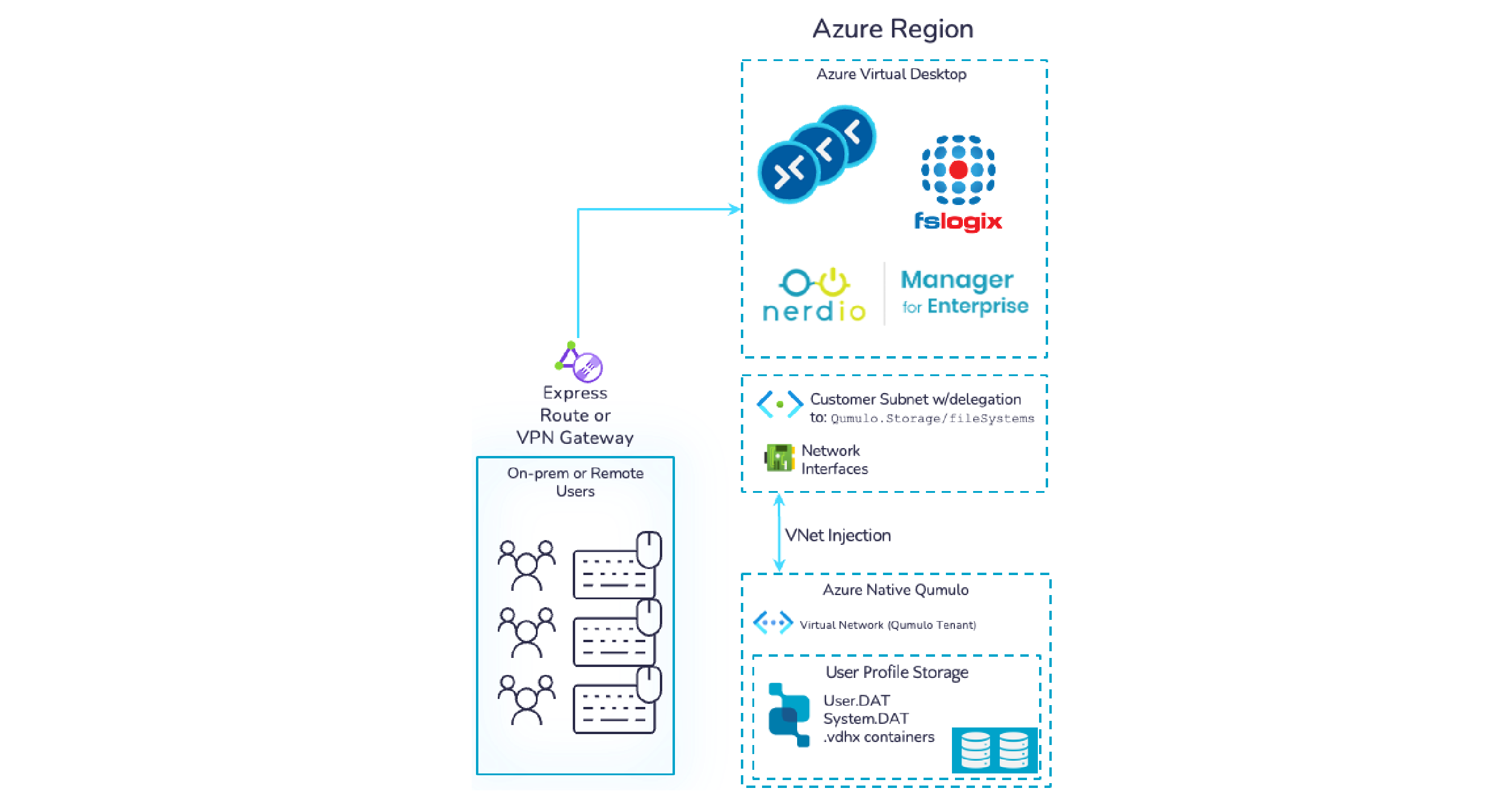
With big data analytics, modern datasets are rapidly becoming too large and complex to process by traditional means. IoT sensors create seemingly insurmountable hurdles for typical data center infrastructure due to the incredible amount of data generated, along with the complexity of storing, processing, and managing this data. Which is why our customers are turning to distributed processing applications that support the extreme scale of big data workloads for use cases such as:
- Seismic research
- Search at scale
- Deep analytics across industries
To support big data analytics for applications like these, enterprises must have robust, integrated and distributed back end storage that supports extremely high throughput. The Qumulo File Data Platform enables organizations to easily capture and store sensor data to build AI models for automation. Our distributed file system scales to multiple petabytes, is easy to manage, and integrates into any automation environment, such as Apache Spark, using Qumulo’s advanced API.
Apache Spark is a unified engine for big data analytics processing, with built-in modules for streaming, SQL, machine learning and graph processing. Watch this 5-minute demo to see how easy it is to manage IoT workflows with Apache Spark and the Qumulo File Data Platform.
Manage your big data analytics with cost-effective performance
Big data storage is a growing concern and the ability to make informed decisions from large datasets is critical for today’s enterprises and research institutions. Qumulo’s software is a modern file storage system that has the performance, scalability and enterprise features required to process big data analytics workloads. See how Qumulo customers rely on us for mission-critical applications, including building smart cars, developing post-production special effects for blockbuster movies, conducting vital COVID-19 research, and managing millions of documents.
Contact us
Like what you see? Then, test drive a fully functional Qumulo environment for free, book a demo or contact us to arrange a meeting.