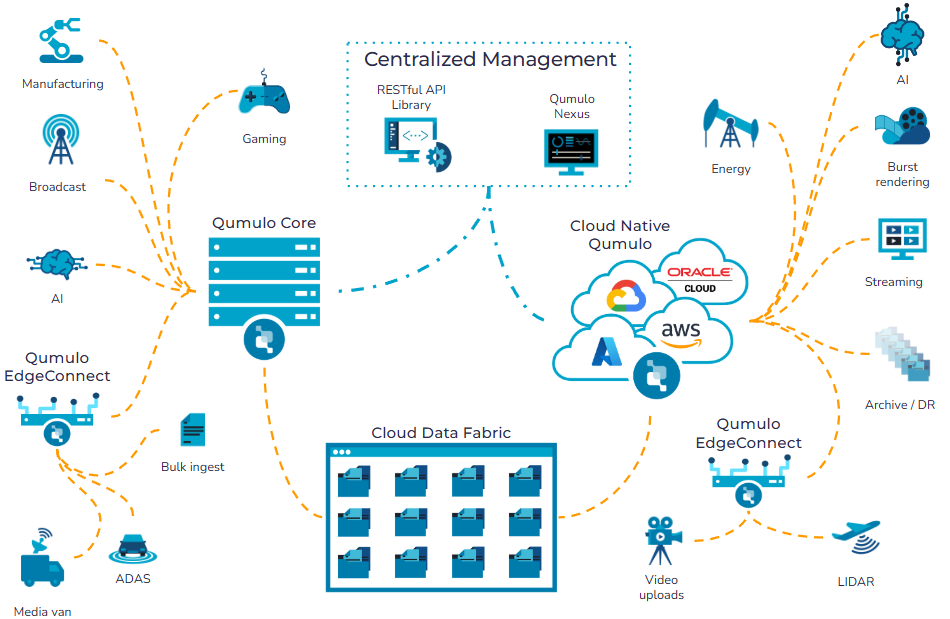
The Qumulo Data Platform combines the world’s most advanced file system with a global namespace, intelligent AI-driven data acceleration, and real-time data analytics, all managed from a centralized portal and via a robust API library to deliver total control over any data, in any location, for any workload, from GPU-powered HPC to cold cloud archives.
This is the new shape of enterprise IT. The future belongs not to static data silos, but to universal data fabrics where active data sets move at the speed of innovation, computation is consumed as a utility, and the most valuable data resides in the places where enterprises can extract the most value. That future is here today, and Qumulo is proud to be the platform that makes it possible.”
Douglas Gourlay
President and CEO of Qumulo
Run Anywhere with any Workload
Our Qumulo Data Platform lets you create data anywhere, enabling you to use it everywhere in real time, whether for on-premises high-performance compute workloads, artificial-intelligence training and inference in the cloud, sensor/machine data ingested at the edge, or low-latency access to petabytes of remote data from a satellite branch or home office.
In the Data Center
Deploy Qumulo Core in your own data center or private cloud, on your preferred hardware from your preferred vendor. Choose from HPE, Cisco, Dell, Supermicro, or Arrow, among others, sized for your specific capacity and performance needs.
Whether you need high-performance, high capacity, or hybrid / multi-cloud file and object data services, Cloud Native Qumulo delivers fully elastic scalability and performance on your choice of public cloud platform, including AWS, Azure, GCP, and OCI.
Get all the scalability and performance of Cloud Native Qumulo as a fully-managed service, deployed in minutes from the Azure Marketplace. Choose from our Hot and Cold versions, customized to support your high-performance and archive workloads.
Use Qumulo EdgeConnect to enable high-speed data ingest from remote or low-bandwidth sites, or to provide local read/write caching, using a lightweight hardware appliance or single virtual machine.
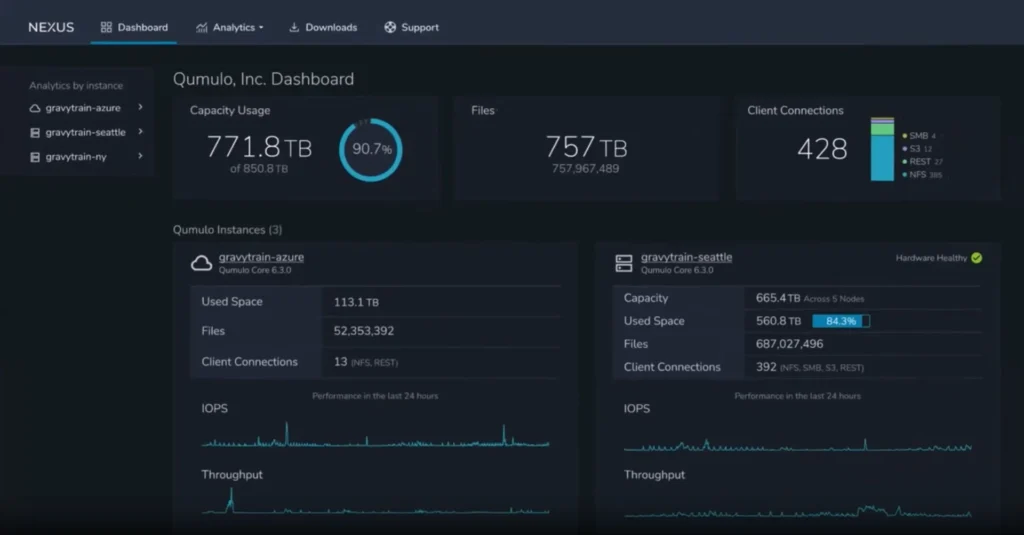
Consolidate all on-premises and cloud unstructured data into a single globally consistent namespace with intelligent caching using Qumulo Cloud Data Fabric, which you can use to power your innovative new AI engines, both cloud-based and on-premises, with the same source data that fuels your legacy on-premises applications. Collaborate in real time from anywhere on any shared data, without complex orchestration or costly data collisions. Manage and monitor your data across the globe at any scale, using Qumulo’s powerful management and analytics tools.
Qumulo frees your workloads from the constraints of location and distance, letting you project data at petabyte scale from where it lives to where it’s needed — whether from your data center to AWS, or from Azure to OCI — and to do it in real time, without having to pre-stage or replicate any of it. The Qumulo Data Platform anticipates which data you’ll need and prefetches it automatically, ensuring it’s ready and in place before you need it.
One worldwide namespace
Unlike other solutions, only Qumulo delivers full read-write access from anywhere in real time, without replication or write-back operations that slow you down when seconds count. The Qumulo Data Platform gives you the best of both worlds: a single global namespace, and low-latency read and write access even to remote data.
One solution for on-premises and cloud
Get full feature parity from every Qumulo deployment, whether on-premises, in any public cloud, or at the edge. Use the same management tools and automated workflows anywhere, and simplify data management and governance even as you enable new AI innovations and discoveries.
No limits, no compromises
Choose the exact configuration you need for your specific workloads. Leverage the scalability and performance of the cloud at the TCO of on-premises storage for all your workloads, from HPC to archive–up to 80% lower cost than other file services in the cloud.
Run Anywhere Your Workflows Do
Beyond AI, your enterprise might have hundreds of different file-driven applications, with no two of them alike. You may have one set of workflows that are exclusively on-premises, while others run solely in the cloud, and maybe a third subset that is a mix of both. Some workflows need high performance while others need capacity. Qumulo eliminates the barriers that have separated on-premises applications from cloud workflows, letting you position your data and workloads exactly where you need them.
High performance when you need it
Customize Cloud Native Qumulo to meet the specific throughput and IOPS requirements of your most demanding cloud-based applications and adjust dynamically as needed. on-premises. For on-premises workloads, choose all-flash (QLC, TLC, SSD, NVMe) hardware from your preferred vendor to build the right high-performance Qumulo Core cluster for your organization.
High capacity when you need it
Deploy capacity-heavy applications on-premises using hybrid (NVMe or flash + disk) hardware from your preferred vendor. Data-dense workloads in the cloud will scale automatically to virtually any size as more data is added, letting you choose the performance tier and price point you need.
Dynamic performance and scalability
Cloud Native Qumulo gives you both the capacity and performance elasticity you need to support virtually any size and throughput requirements – even if they change by the hour – whether on AWS, Azure, GCP or OCI.
Cryptographic isolation and multi-tenancy
The Qumulo Stratus Architecture defines a new standard for data isolation, performance, manageability, and cost-effectiveness. Built on Cloud Native Qumulo, it offers all the same features and ease of use, with cryptographically assured tenancy, strict tenant isolation, and tenant-specific enterprise services, none of which can be easily implemented on-premises using legacy architectures.
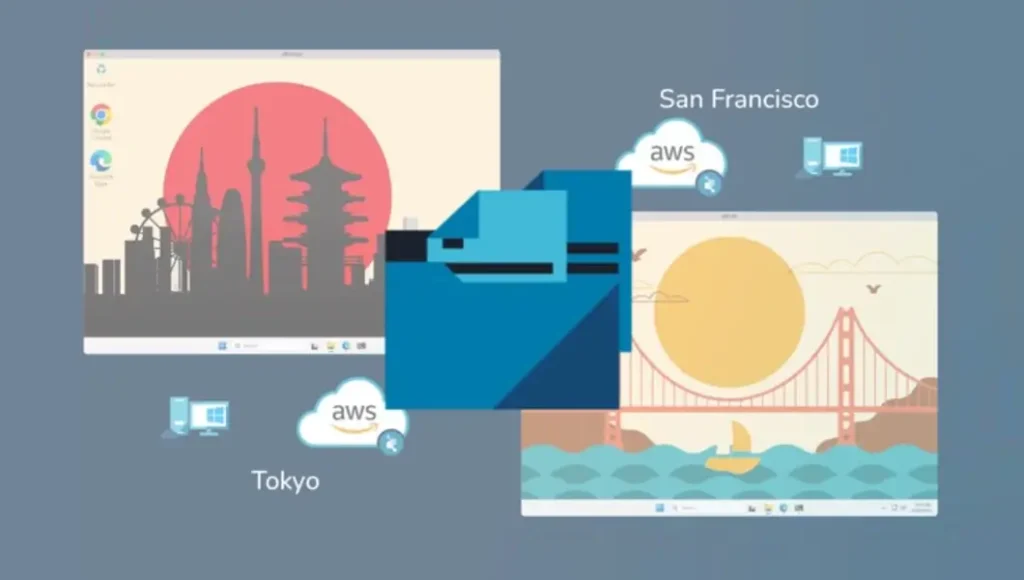
One Global Namespace with Intelligent Local Caching for Every Workload
No matter where it actually resides in your organization, Qumulo’s Data Platform enables you to present all your unstructured data everywhere to any application, AI engine, or client as a single, unified dataset that can be accessed, used, and updated everywhere in real time. You can ingest data from a remote edge location and begin analyzing it, modifying it, or transforming it from any data center worldwide or from any cloud region in real time.
All Data Is Local
All users and applications everywhere have the same view of the same data – always up-to-date, always available. Data hosted remotely is cached locally to keep latency to a minimum. All saves are committed locally to mirrored flash storage and propagated as needed to all other endpoints in real time.
Qumulo NeuralCache, a core component of every Qumulo deployment, closely monitors per-client and per-application data-access patterns and anticipates which data each client will need next. It prefetches that data from its source into a local cache tier, ensuring that each workload gets the data it needs, minimizing both disk and WAN latency.
No Waiting
In addition to minimizing read latencies, NeuralCache eliminates the need for prestaging data, which in turn means your creative teams and AI workflows aren’t kept waiting for data to traverse the WAN.
The unique architecture of the Qumulo Data Platform preserves bandwidth by minimizing cross-site data transfers, and minimizes read latencies even for remote data by prestaging relevant data in local cache before it’s even requested.
One Data Platform for Every Industry and Every AI Workload
Whether on-premises, in the cloud, or at the edge, Qumulo’s Data Platform lets you leverage all your data everywhere to power your high-performance applications and AI workflows in any location, with total control over access, usage, and outcomes.
Medical Imaging
Qumulo unifies petabyte-scale image archives, PACS, and AI diagnostics into a single, high-performance data platform for digital pathology and healthcare imaging. The Qumulo Data Platform enables secure real-time access to billions of files spanning hospitals, research centers, and cloud AI to deliver faster diagnoses, streamlined collaboration, HIPAA compliance, and accelerated AI training for life-saving insights.
Qumulo enables cost-effective Next-Generation Sequencing workloads and large-scale, comprehensive proteomics analysis, and globally distributed research teams, simplifying the management and curation of exabyte-scale datasets to develop new data-driven treatment techniques.
Storing subsurface modeling data is challenging due to its large size and complex format — especially when data is generated, stored, and consumed at various locations at the edge, in core data centers, and in the cloud. Qumulo’s high-performance data platform accelerates business-critical subsurface workflows, reducing time-to-results and lowering costs.
The financial sector runs on data, demanding high-performance and the highest standards of data security and regulatory compliance. Qumulo‘s exabyte scalability delivers cost-effective capacity for long-term document retention, while our elastic performance and global namespace simplify real-time analysis of large-scale datasets for portfolio and risk management.
Qumulo enables digital artists to access data and collaborate with globally distributed teams in real time, accelerating key workflows and differentiating their abilities in a crowded industry. The Qumulo Data Platform enables studios and creative teams to quickly burst to the cloud for animation and rendering, or to streamline post-production editing between editors, visual effects artists, and sound-designers regardless of location.
Qumulo’s Data Platform enhances the research capabilities of research universities and labs, creating a unified data fabric that integrates on-premises infrastructure and cloud storage across campuses, facilities, and institutions. Qumulo enables research teams and organizations to gain key insights, and to quickly leverage AI and HPC services in the cloud to drive groundbreaking discoveries and breakthroughs.
Our customer success team is not incentivized to close tickets, but to solve your issues as efficiently as possible, sometimes before you even notice them!
Resolution Is Just a DM Away
Qumulo enables digital artists to access data and collaborate with globally distributed teams in real time, accelerating key workflows and differentiating their abilities in a crowded industry. The Qumulo Data Platform enables studios and creative teams to quickly burst to the cloud for animation and rendering, or to streamline post-production editing between editors, visual effects artists, and sound-designers regardless of location.
Qumulo also integrates with your preferred enterprise monitoring tools, such as Splunk, SolarWinds, Prometheus, and others, to ensure that system events and log data are tracked using the same standards as your other business-critical enterprise and data services.