An era of unprecedented data scale
The fundamental nature of how companies use computing to drive innovation, agility, and responsiveness has changed significantly over the past five years. While organizations have historically relied on data to drive business, that data was often expensive to acquire and store.
Over the past five years, we have seen a dramatic reduction in the economics of data creation, and an equally dramatic reduction in the cost of data storage. We’ve evolved from the era of “How do I store data?” to “How do I intelligently and efficiently manage data?” Plus we’re in an era where billions of files – or more – are the norm.
This is the era of unprecedented data scale. This data is produced and consumed by file-based applications and systems which make up the foundation of modern digital production pipelines. This means that companies are now generating significantly more file-based data than ever before.
As a result, businesses are fast outgrowing their legacy file systems, and can no longer manage their massive collections of digital assets. Yet, these assets remain at the core of the business, and file-based workflows are the crucial pipelines for those assets.
In today’s world of abundant data, there’s no limit on the number of files – billions or trillions of files aren’t just possible, but are becoming commonplace. There’s also no limit on file size at the extremes—small and large, and no limit on availability, whether on-premise, in the cloud or in geographically distributed data centers.
The move from large-scale to hyperscale
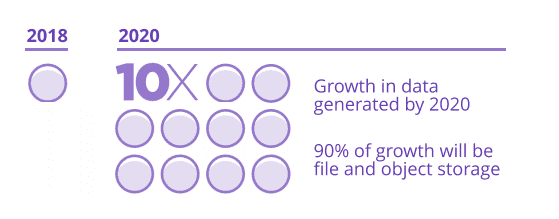
IDC predicts that the amount of data created will reach 40 zettabytes (a zettabyte is a billion terabytes) by 2020, and that there will be more than 163 zettabytes by 2025. This is ten times the data generated in 2016.
Approximately 90 percent of this growth will be for file and object storage.
There are four trends contributing to the amount of data companies must store:
- The vast increase in machine-generated data;
- The prevalence of video as a data type across all industries;
- The ever-increasing resolution and fidelity of these digital assets, and
- Longer data lifespans, and trends toward globalization that create distributed computing and storage resources.
Machine-generated data
Successful companies increasingly rely on machine-generated data for core business operations and insight. The Internet of Things (IoT) is powering a transformation in the value of data for enterprises of all kinds, spanning all data-intensive industries.
Data is powering value and growth as never before. For example, large machine-generated data sets in life sciences are making groundbreaking discoveries and life-saving medical treatments available. Because of its tremendous value to researchers, healthcare providers, and patients, the need for such data will only grow.
As another example, oil and gas companies are using data to create tremendous value for their customers. It’s not an exaggeration to say that the greatest assets for these organizations are the file-based seismic data used for natural gas and oil discovery.
Higher-resolution digital assets
Technical advances in hardware and software systems are enabling new capabilities for businesses of all kinds.
For example, media and entertainment companies are now able to standardize around uncompressed 4K video, with 8K on the horizon. This level of fidelity for truly immersive viewing experiences was unthinkable just a few years ago.
The resolution of digital sensors and scientific equipment is also constantly increasing. Higher resolution causes file sizes to grow more than linearly – a doubling of the resolution of a digital photograph, for example, increases its size by four times.
As the world demands more fidelity from digital assets, its storage requirements grow.
Longer data life spans
At the same time, the advent of machine learning has enabled entirely new sources of value for businesses and their customers. It’s now possible to take advantage of millions or billions of individual pieces of data, and have systems identify patterns, sources of value, areas of opportunity and risk that simply weren’t possible before. These huge advances in data analysis and machine learning makes data more valuable over time.
For enterprises, this has placed tremendous strain on their applications, and on the storage those applications depend on. Scrambling to adapt to the new landscape of possibilities, businesses are forced into a “better to keep it than miss it later” philosophy when it comes to their data.
The public cloud has changed the very nature of how applications are built and deployed. The trends towards businesses delivering tremendous value to their customers from massive data footprints, and the development of sophisticated analytical tools, were paralleled by the advent of the public cloud. Its arrival overturned basic assumptions about how computing could be done, and how storage should work.
This has created a profound shift in not just the pace of business innovation, but who is setting that pace. The ease with which line-of-business managers can create and manage data, and deploy applications to take advantage of this data, is placing strains on many of the technology organizations supporting businesses.
Global reach
The cloud means business leaders can drive innovation and value for their customers faster and more efficiently while taking advantage of resources that behave elastically.
The shift from capex- to opex-based technology expenses has transferred the decision-making and pace of innovation from centralized technology organizations to business managers. It has resulted in rapid adoption of new technologies, enabled by elastic access to the compute resources required to deliver them. And this elasticity extends to geographies, making global reach achievable without building physical data centers across the world.
New ways of solving problems and delivering customer value have arrived, and are here to stay. All businesses realize that, in the future, they will no longer be running their workloads out of single, self-managed data centers.
Instead, they will be moving to multiple data centers, with one or more in the public cloud. This flexibility will help them adapt to a world with distributed employees and business partners.
Companies will focus resources on their core lines of business instead of IT expenditures. Most will improve their disaster recovery and business continuity plans, and many will do this by taking advantage of the elasticity provided by the cloud.
The disruptive realities of file storage challenges companies to find new solutions and approaches for their file-based workflows and assets.
The challenge facing storage solutions
Users of applications dependent on legacy scale-up and scale-out file systems – the traditional work-horses of file-based data – are finding those systems inadequate for today’s elastic computing reality, and its future potential.
One key challenge is the inability to understand the very nature of what data you have; its value is reaching a critical limitation imposed by legacy systems. That limitation impacts how legacy systems manage the metadata of large file systems—their directory structures and file attributes themselves become big data.
Legacy solutions that rely on brute force to give insight into the storage system have been defeated by scale. Brute force methods are fundamental to the way legacy file systems are designed and cannot be fixed with patches.
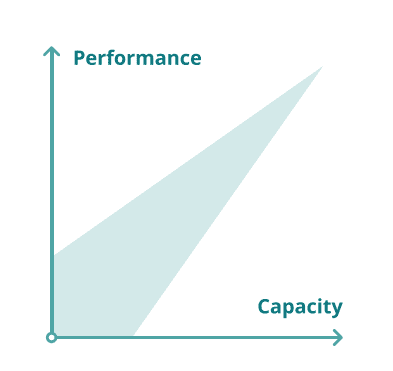
Another limitation preventing legacy systems from performing in this new elastic world is that they were never designed for “elastic” scale—meaning scaling across small and large file sizes, as well as geographic locations.
Traditionally, companies faced two problems in deploying file-based storage systems: they needed to scale both capacity and performance.
With elastic storage, capacity means more than creating a large repository of terabytes of raw storage. In today’s world of all data being valuable, scale is no longer limited to these two axes.
New criteria for scale have emerged. They include the number of files stored, the ability to control enormous data footprints in real-time, global distribution of data, and the flexibility to leverage elastic compute in the public cloud in a way that spans the data center as well.
Against this backdrop of profound disruption, the traditional buying criteria have not lost relevance. Price, performance, ease-of-use and reliability remain as important as ever, no matter how much the landscape has evolved.
Today’s changing storage landscape places enterprise customers at a crossroads. They will struggle to cope with massive amounts of data. They will struggle to meet the demands for global reach, with few good options for file-based data that spans the data center and the public cloud.
Attempted solutions: Object and subdividing by volume
Understandably, there have been incremental attempts at addressing this growing need for elastic file storage at large scale. But for reasons outlined below, these approaches are architecturally inadequate to address the significant demands of elastic storage and the demands businesses require in this age of elastic storage.
Object storage
Object storage allows for very large systems with petabytes of data and billions of objects, and works well for its intended use. In fact, it’s becoming conventional wisdom to assert that object storage technologies are the solution to the scale and geo-distribution challenges of unstructured storage.
Cloud providers believe whole-heartedly in object storage. Today, a customer wanting to store data in the cloud is practically forced to use it regardless of use case.
Some companies are attempting to adopt object storage in use cases for which it was never intended, and for which it is a poor fit. In order to achieve their scale and geo-distribution properties, object stores have intentionally traded off features many users need and expect: transactional consistency, modification of objects (e.g. files), fine-grained access control, and use of standard protocols such as NFS and SMB, to name a few.
Object storage also leaves unhandled the problem of organizing data. Instead, users are encouraged to index the data themselves in some sort of external database. This may suffice for the storage needs of stand-alone applications, but it complicates collaboration between applications, and between humans and those applications.
Modern workflows almost always involve applications that were developed independently but work together by exchanging file-based data, an interop scenario that is simply not possible with object storage. Further, object stores don’t offer the benefits of a file system for governance.
Subdividing into volumes
Another approach to handling large amounts of data on legacy file systems is to partition the files into separate volumes, which means multiple namespaces. Volumes are silos of file data.

Separate volumes always mean wasted storage space. Each volume contains reserve capacity, and if you add up all the reserve capacity of all the volumes you have a substantial amount of wasted capacity.
Separate volumes mean inefficiency, which translates into higher storage and infrastructure costs.
Collaboration is fundamental to many file-based workflows but it can only happen if everyone has access to the data. Because volumes create isolated data silos, information must be copied from one silo to another, which is both time-consuming and inconvenient.
In a single namespace system, there is a centralized storage repository that anyone with the correct permissions can access.
A single namespace makes collaboration and cooperation possible.
Multi-volume approaches can limit how well the file system’s performance can scale because administrators must allocate throughput to specific volumes. This means that high traffic volumes can become bottlenecks. With a single namespace, aggregate throughput is spread over a broader set of users and applications, which reduces the chance of bottlenecks.
It’s difficult to manage separate volumes in terms of permissions, capacity planning, user or project quotas, backups and other tasks because administrators have a fragmented view of the file system. A single namespace gives a unified view, making it much easier to see how the file system is being used.
Elastic storage file fabric enables flexible consumption of file storage
Elastic file storage scales to billions and trillions of files.
The notion that capacity is only measured in terms of bytes of raw storage is giving way to a broader understanding that capacity is just as often defined by the number of digital assets that can be stored. Modern file-based workflows include a mix of large and small files, especially if they involve any amount of machine-generated data.
As legacy file systems reach the limits of digital assets they can effectively store, buyers can no longer assume that they will have adequate file capacity.

The elastic file storage scales across operating environments, including public cloud. Proprietary hardware is increasingly a dead-end for users of large-scale file storage. Today’s businesses need flexibility and choice. They want to store files in data centers and in the public cloud, opting for one or the other based on business decisions only, and not technical limitations of their storage platform.
Companies want to benefit from the rapid technical and economic advances of standard hardware, including denser drives and lower-cost components. They want to reduce the complexity of hardware maintenance through standardization and streamlined configurations.
The trend of smart software on standard hardware outpacing proprietary hardware will only increase.
Users of large-scale file storage require their storage systems to run on a variety of operating environments and not be tied to proprietary hardware.
An elastic file fabric enables flexible consumption of file storage. A flexible, on-demand usage model is a hallmark of the public cloud. However, the shift to cloud has stranded users of large-scale file storage, who have no effective way to harness the power the cloud offers.
An elastic file fabric scales across geographic locations with data mobility. Businesses are increasingly global. Their file-based storage systems must now scale across geographic locations. This may involve multiple data centers, and almost certainly the public cloud.
A piecemeal approach and a label that says “CLOUD-READY” won’t work. True mobility and geographic reach are now required.
An elastic file fabric provides real-time visibility and control. As collections of digital assets have grown to billion-file scale, the ability to control storage resources in real-time has become an urgent new requirement.
Storage administrators must be able to monitor all aspects of performance and capacity, regardless of the size of the storage system.
An elastic file fabric gives access to rapid innovation.
Modern file storage needs a simple, elegant design and advanced engineering. Companies that develop modern file storage will use agile development processes that emphasize rapid release cycles and continual access to innovation. Three-year update cycles are a relic of the past that customers can no longer tolerate.
Elastic fabric is the future of file storage
File-based data becomes transformative when it gives people the freedom to collaborate, to innovate, and to create. It fuels the growth and long-term profitability of modern, data-intensive enterprises.
File-based data is more important than ever and companies must find better ways to access and manage that data. To meet the challenge, companies must adopt modern file system technologies that enable an elastic file fabric.
Reliability, high capacity and performance are table stakes. Beyond that, companies need global access and elastic scale, including the ability to scale to billions of files. The file storage system must move data where it’s needed, when it’s needed, and do all this with lower cost, higher performance, more reliability and greater ease of use than legacy systems.
Elastic fabric is the future of file storage for the companies that will remain competitive, innovative and agile in the digital era.