
Qumulo and Databricks have completed a joint integration that lets enterprise lakehouses span an organization’s entire data estate. Wherever the data lives, on-premises, at the edge, or in any major cloud, Databricks can now read, write, and govern it through Qumulo storage.
The lakehouse has become the foundation of modern data analytics by combining the openness of a data lake with the governance and reliability of a data warehouse. Organizations adopt it to escape vendor lock-in, lower costs, and unify their analytics and AI on a single platform. But until now, lakehouses have largely been confined to a single site or cloud provider’s object storage in a single region. This has served the industry well, but most enterprises have their raw and bronze level data everywhere: factory sensors, branch-office data, medical imagery, application logs, transactional records, all generated and retained across data centers, edge sites, and multiple clouds. IDC projects enterprise unstructured data growing at approximately 16% CAGR through 2028 to 10.5 ZB, fueled by sensor proliferation, IoT, and AI workloads. Bringing the lakehouse to all of that data, wherever it lives, is the next architectural step.
Qumulo is a software-defined data platform that runs across on-premises, edge, and cloud as a single global namespace. Together with Databricks, it enables the lakehouse to extend across the full data estate without requiring data to be copied or consolidated into one cloud bucket. The same governed tables can be queried by Databricks in one region, by a training job on-premises, and by a BI tool in another cloud, against one source of truth.
This post introduces three validated integration patterns between Databricks and Qumulo to enable different lakehouse architectures: (1) run Databricks analytics and AI directly against data on Qumulo, with no re-platforming or migration; (2) bring Qumulo-resident tables under Unity Catalog governance, for a single governed view regardless of where the data lives; and (3) share Qumulo data, read-only, with other Databricks workspaces, other clouds, and non-Databricks tools through open Delta Sharing. For step-by-step deployment guidance, see the Qumulo and Databricks Integration Note.
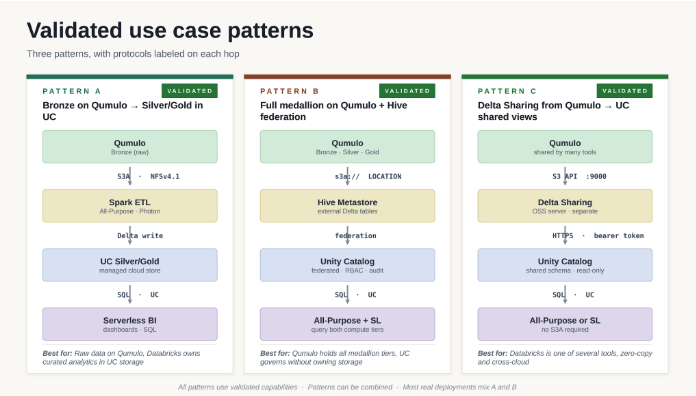
Figure 1. High Level Architecture of Qumulo-Databricks integration patterns
Benefits for Databricks teams
These patterns deliver three outcomes for organizations adopting Databricks:
- Faster time to results. Existing data on Qumulo from raw logs, imagery, telemetry, genomics, and application records is read by Databricks in place, eliminating bulk migration costs and time and per-request S3 API charges. Under validation test loads, Qumulo saw API-related storage costs reduced by 60% or more and time-to-first-results compressed by 40% or more compared to equivalent workflows that staged data through cloud object storage first.
- One copy, many consumers. The same data is used concurrently by Databricks in the cloud, by training jobs on-premises, by edge applications, and by other analytics and AI tools. Everyone works against a single source of truth instead of versions drifting apart across environments.
- Unified governance without bulk migration. Tables on Qumulo are governed through Unity Catalog, with permissions, audit, and lineage applied consistently to analysts and BI teams across notebooks and dashboards.
Three validated patterns
Each pattern positions the data and the governance differently, and most production deployments combine them. It should be noted that customers can deploy a combination of these integrations.
Pattern A. Qumulo holds raw and historical data, Databricks holds the curated tables. Databricks compute reads source data on Qumulo, applies Silver and Gold transformations, and writes the curated Delta tables into Unity Catalog managed storage. Serverless SQL Warehouses query the Gold tables for BI and analytics. Best when an organization is starting with Databricks and wants its first curated layer governed natively by Unity Catalog.
Pattern B. All medallion tiers (Bronze, Silver, Gold) live on Qumulo as Delta tables. The tables are registered in a Hive Metastore that Databricks federates into Unity Catalog. All-Purpose Compute reads and writes through this path; Serverless SQL Warehouses query through Unity Catalog. Best when an organization wants its full lakehouse to remain on Qumulo while still benefiting from Unity Catalog governance, lineage, and audit.
Pattern C. An open-source Delta Sharing server exposes Qumulo Delta tables to Unity Catalog and to other consumers, read-only. Databricks and other tools receive short-lived access through the Delta Sharing protocol; data is never copied to the consumer. Best when Qumulo data is shared with multiple consumers (other Databricks workspaces, Snowflake, BI tools) or across clouds.
Step-by-step procedures for all three patterns are in the Qumulo and Databricks Integration Note.

