
Cloud Native Qumulo scaled to 1.6 TB/s on AWS, and that’s not even the best part. Here is what it means for you.
For years, enterprise customers have voiced the same concern about the cloud:
“It just isn’t fast enough.”
“Even if it were, we can’t reliably get enough compute in one availability zone.”
One customer put the challenge plainly:
“We need to exceed 1.5 TB/s of sustained throughput in the cloud, without sacrificing reliability or flexibility.”
That capital “B” in TB matters. This is bytes, not bits. One byte equals eight bits, so 1.5 TB/s translates to roughly 12 terabits per second of sustained data movement. And sustained matters just as much. This is not a short-lived burst or a cache-assisted spike, but continuous throughput maintained over time.
To put that number in context, streaming a single 4K movie typically requires ~25 megabits per second. At 12 Tb/s, the same system could theoretically support nearly half a million simultaneous 4K streams.
And for those who are wondering, Qumulo CNQ rose to the challenge, reaching 1.6 TB/s and 20.7 million IOPS, but more on that later.
In fact, performance numbers alone were never the real concern. Few companies need 1.5 TB/s today, but experience tells us that only planning for current demand rarely ends well. Building high-performance systems from cloud resources is often a matter of budget, risk tolerance, and system fragility. Indeed, building for speed alone is a great way to get on a first-name basis with the CFO in many organizations – not in a good way. Combining speed with a brittle infrastructure architecture may temporarily solve one challenge, but it creates many additional technology and economic challenges as knock-on effects.
Solving the root problem of architectural flexibility requires new thinking.
Most cloud storage platforms force customers to make long-term infrastructure decisions early. Performance, availability, and cost are tightly bound together, requiring overprovisioning for peak demand, duplicate data for resiliency, or anchor workloads to specific locations. Once those choices are made, they are difficult and expensive to undo.
As a result, storage becomes the constraint that compute teams plan around rather than a flexible foundation that adapts to changing workloads.
The better question customers should be asking is not, “How fast can this thing go?”
It is this: Can the cloud deliver crazy extreme performance when I need it, without locking me into brittle architectures, duplicated storage, or permanently overprovisioned infrastructure?
Qumulo took that challenge seriously. Not by chasing a headline number, but by proving a different operational model. And that is why 1.6TB/s is NOT THE HEADLINE. You might ask, “Qumulo, if scaling to 1.6 TB/s on AWS, isn’t the headline, what is?”
What if the real headline wasn’t about speed at all, but about removing zonal constraints without paying an economic tax?
The answer starts with a cloud-native architecture, not a retrofitted one.
Built for the Cloud from the Beginning
Qumulo’s architecture was designed for the cloud, not adapted to it. That distinction matters.
Most cloud file storage systems did not fail due to poor execution. They failed because they inherited assumptions from a hardware-defined era and never fully re-architected for cloud-based operations.
Traditional file systems were built on a simple physical truth: storage hardware defined both capacity and performance. More disks meant more space, and more space meant more throughput. Capacity and performance were physically coupled. You could not meaningfully scale one without the other. That model made perfect sense when organizations were buying spinning disks, racking servers, and wiring their own networks.
When cloud providers introduced managed file services, many of those same assumptions carried forward.
Some services scale capacity automatically, but performance remains tied to the amount of data stored. Others require customers to provision capacity and throughput together as fixed attributes. Elasticity exists, but it is constrained by the same coupling that existed on premises.
Because performance and capacity remain linked, customers are left with two unappealing options:
- Provision for peak: pay for maximum performance and capacity at all times, even when utilization is low
- Provision for average: save money until workloads hit a wall and performance becomes the bottleneck
Most teams choose the first option because the cost of throttled workloads or missed deadlines far exceeds the cost of overprovisioning; however, paying for what you might need is the opposite of cloud economics.
The problem compounds when protocol diversity enters the picture. Linux environments expect NFS. Windows environments require SMB. Modern applications increasingly rely on object access via S3-compatible APIs.
The result is fragmentation. Different services, different scaling models, different operational behaviors. Teams running mixed workloads often manage multiple storage systems, each optimized for a narrow use case.
Over time, storage becomes the constraint that compute teams plan around.
“How much storage do we have?” They ask, “What can we run?”
This is backwards. Infrastructure should adapt to workloads, not the other way around.
Cloud Native Qumulo breaks that coupling.
From inception, CNQ separated performance from capacity by design. Compute scales independently from durable object storage, with performance added or removed by adjusting compute resources rather than preallocating capacity. Customers only pay for the storage they consume, while performance becomes an elastic attribute rather than a fixed commitment.
This allows CNQ to support general-purpose enterprise file services economically while scaling to specialized, high-intensity workloads without forcing customers into permanent overprovisioning or fragmented storage silos.
That makes the headline clear: CNQ Designed for the Cloud, Not Adapted to It. Still, something feels missing.
The Challenge: Go Faster Than On Premises, Without a Safety Net
The customer requirement was not theoretical.
On-premises, the workload ran in a single data center, with compute placed close to storage to minimize latency. If infrastructure failed, whether power, cooling, or networking, the workload would stop. Disaster recovery existed, but, like most DR systems, it was asynchronous, lightly tested, and unable to sustain full workload performance.
The system worked, but it was fragile.
Traditionally, moving to the cloud was never about speed. It was about removing single points of failure without introducing new constraints. But if it could be fast, how would that affect our customers’ businesses?
In the cloud, the expectations were clear:
- Exceed on-premises performance
- Avoid dependence on a single Availability Zone
- Maintain full performance during failures
- Do it without doubling storage costs
This last requirement is where many cloud file systems fall short.
Most multi-Availability Zone offerings utilize replication. Full copies of data are maintained in each zone to provide availability. While effective for durability, this approach comes with real consequences. Storage costs increase linearly with the number of zones. Write performance is reduced due to cross-zone coordination. Multi-AZ becomes something customers reserve for failure scenarios rather than for normal operation.
At the same time, compute availability in the cloud is not evenly distributed.
GPU- and CPU-heavy workloads often face capacity constraints that vary by zone and over time. A design that anchors data to a single zone forces compute to follow, even when capacity exists elsewhere in the region. Customers end up hunting for instances, reserving compute before data is ready (which is costly), or delaying work altogether (which extends time-to-results).
The customer challenged Qumulo with speed, reliability, and resiliency. The solution must deliver higher performance while removing zone-level dependency, eliminating storage duplication, and allowing workloads to run wherever compute capacity is available at any given moment.
Qumulo solves that problem at the architectural level, rather than layering availability on top of legacy assumptions.
The Architecture: Multi-Availability Zone by Design, Not by Duplication
At the core of this deployment was a multi-AZ CNQ cluster, evenly distributed across three Availability Zones within a single AWS Region.
An Availability Zone, or AZ, is a physically separate set of one or more data centers within an AWS Region. Each AZ is designed to operate independently, with its own power, cooling, and networking, while being connected to other AZs in the region through high-bandwidth, low-latency links. This separation allows applications to remain available even if an entire data center location experiences an outage.
Durability is provided by Amazon S3 at the regional level, where data is automatically protected across multiple facilities. This is why AWS delivers 11 nines (99.999999999% durability), widely regarded as the industry benchmark for data protection.
By design, CNQ’s architecture spans multiple AWS Availability Zones without requiring full replicas of customer data in each zone. As a result:
- Storage cost is identical whether CNQ runs in one AZ or multiple AZs
- Write performance is not penalized by cross-zone replication
- Multi-AZ operation is the normal state, not a failure mode
Note: Typically, multi-AZ services cost twice as much as their single-AZ implementations. Keeping the cost the same is a significant economic benefit.
If one Availability Zone becomes unavailable, the cluster continues operating in the remaining zones with no data loss and no need to fail over to a secondary copy.
This design is simpler, faster, and materially cheaper than replica-based multi-AZ approaches.
It would be easy to make this the headline: CNQ Architecture Delivers Multi-AZ Resilience Without Data Duplication. Not wrong. But we can do even better.
The CNQ Multi-Availability Zone Advantage for GPU-Intensive Workloads
Multi-AZ is usually discussed as an availability feature, which is fine, but nowadays, availability is considered table stakes. What actually matters is what CNQ unlocks for compute, namely making GPU and CPU acquisition far less painful.
Most cloud file systems, even those marketed as multi-AZ, anchor storage to a single primary zone. Compute must follow the data. If GPUs or CPUs are unavailable in that zone, the workload stalls, even when unused capacity exists elsewhere in the region.
This forces teams to hunt for GPUs and CPUs. First, they search for scarce compute instances. Then they reserve and pay for that compute before it can be used. Next comes the data problem. Large datasets must be copied or re-staged wherever the compute was found. Only after all these steps are complete can the work resume. CNQ removes that constraint.
With CNQ, compute in multiple Availability Zones can access the same dataset simultaneously. Customers can aggregate capacity across zones into a single logical pool without copying or re-staging data.
If GPUs are available in one zone on Monday and another zone on Tuesday, customers do not move data or rebuild infrastructure. They simply point the existing CNQ deployment to wherever compute is available.
From a customer perspective, this enables:
- Faster access to scarce GPUs and CPUs
- No data re-staging or copy phases
- No replication penalties
- No increase in storage cost
Work can begin immediately because the data already exists in every Availability Zone within S3, which serves as the persistent storage layer. Unlike Amazon Elastic Block Store (EBS) or instance-attached storage, this architecture does not require copying or rehydrating data into each zone before compute can start. Instead, the file system accesses data locally in each AZ through NeuralCache. This approach eliminates weeks-long data staging efforts and keeps expensive compute resources fully utilized from the start.
Once again, you might be thinking: surely this has to be the headline: CNQ and the Art of Making GPU Hunting Bearable. We are on the right track. Let’s see if we can top it.
Scale Performance as High as You Want, Then Scale It Back Down
The customer asked to exceed 1.5 TB/s of sustained throughput in the cloud, without sacrificing reliability or flexibility. Qumulo created a test deployment that ultimately exceeded expectations, achieving 1.6 TB/s of sustained aggregate throughput and 20.7 million IOPS. Indeed, these numbers are impressive (future readers, please see the publication date for context), but are they peak or average requirements? And if you are a customer reading this and are interested in 1.6TB/s and 20.7 million IOPS, not to worry, we’ve got you! See below.
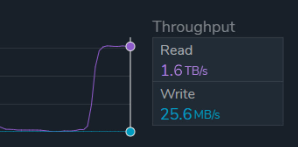
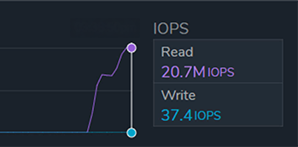
Many customers prioritize flexibility and need the ability to scale resources up and down as demand changes. As discussed earlier, customers often choose between provisioning for peak demand at high cost or sizing for average usage and risking performance shortfalls. This trade-off highlights the core value of the cloud: variability. This configuration can cost roughly $5,000 per hour, which makes it valuable when needed but economically impractical to run continuously. The ability to consume this level of performance only when required makes a cloud-based approach economically viable compared to on-premises infrastructure.
CNQ lets customers reach peak performance without paying for peak capacity all the time. That’s the difference.
With many cloud file systems, performance is tied to permanently provisioned capacity. If you size for peak, you pay peak pricing all the time, even when the workload subsides.
CNQ decouples those decisions.
Customers can aggressively scale performance to meet a deadline, a training window, or a production surge, and then scale back down once the peak has passed. You do not lock yourself into a redline configuration just to cover occasional spikes.
This elasticity applies not only to scale, but to instance choice. In this deployment, instance types were adjusted mid-design due to regional capacity constraints. The cluster simply grew to 250 nodes, sustaining roughly 333,000 connections, using lower per-node bandwidth without requiring any redesign.
Later, customers can transition to newer instance families at lower cost using rolling replacement, without downtime or data migration.
Together, we have finally discovered the headline: CNQ offers Peak Performance Without Peak Commitment. Right? But why would anyone need this amount of peak performance?
The Moments That Demand Extreme Peak Performance
Not every workload needs extreme throughput, and that is exactly the point.
This architecture is not about always running at 1.6 TB/s. It is about having the option to run that fast when time matters, without being financially or operationally punished the rest of the time.
What feels excessive today has a habit of becoming tomorrow’s baseline. So, why would anyone need this performance?
Consider an energy company deciding whether to lease a billion-dollar well. The question is not whether the analysis costs a few million more in cloud spend. The question is who gets to the answer first. Being early can determine who secures the asset and who walks away empty-handed.
In healthcare, faster genomic analysis can mean the difference between prolonged uncertainty and a life-saving treatment decision.
In media and entertainment, speed can determine whether a project hits its release window or whether delays cascade into unplanned costs that erase profit margins. Faster rendering, faster analysis, and faster iteration mean fewer idle creative teams waiting on infrastructure.
Across all these examples, the constraint is not the amount of data that can be stored. It is time to insight and time to decision. When infrastructure delivers answers faster, organizations are not just running workloads more quickly; they are also delivering results faster. They are compressing entire decision cycles and unlocking more value from their most expensive and irreplaceable resource, expert human time.
Imagine what your business could achieve when performance scales up and back down, you stop paying for idle headroom, and start paying for outcomes.
Surely the headline must be: Stop Waiting on Infrastructure. CNQ Delivers Results Faster. But does this really capture it all?
The Qumulative Effect
By delivering 1.6 TB/s of sustained aggregate sequential-read throughput, Qumulo exceeded the original customer performance objective by more than 50 percent compared to on-premises systems. Achieving this level of performance required a cloud-native architecture built entirely on standard AWS infrastructure and spanning three Availability Zones.
More importantly, this work shows that extreme performance does not require unaffordable trade-offs.
Alongside the 1.6 TB/s throughput, the system achieved 20.7 million IOPS with sub-millisecond latency.
But the real value goes beyond the numbers. The architecture allows customers to apply compute across all Availability Zones rather than being confined to a single zone, making large-scale GPU and CPU acquisition significantly easier. It also validates the resiliency of CNQ on AWS, delivering outstanding data availability and eleven nines of durability, without inflating storage costs through duplication. Customers retain the flexibility to choose instance families that match their performance needs and budgets, paying only for what they actually use.
Taken together, these capabilities create a cumulative effect, what we call the Qumulative Effect.
Maybe it is not just one headline that should grab your attention. Maybe it is all of them.
- Cloud Native Qumulo Scaled to 1.6 TB/s on AWS
- CNQ Designed for the Cloud, Not Adapted to It
- CNQ Architecture Delivers Multi-AZ Resilience Without Data Duplication
- CNQ and the Art of Making GPU Hunting Bearable
- CNQ Offers Peak Performance Without Peak Commitment
- Stop Waiting on Infrastructure. CNQ Delivers Results Faster
That combination is the story.
The Takeaway
This deployment proved that a cloud-native file system can deliver extreme performance without trade-offs:
- Multi-AZ by design, not by duplication
- Performance that scales up and scales back down
- Freedom to run where compute is available, not where data is pinned
- Resulting in faster time to results
The cloud does not just have to be fast enough. With the right architecture, it can be more flexible, more resilient, and more economical than on-premises systems ever were.

