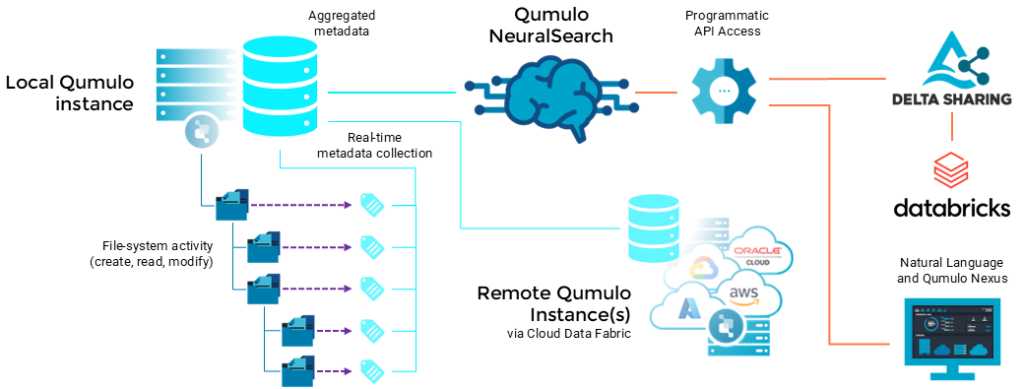
Native cloud object storage integrations often require organizations to move data before AI workflows, such as those in Databricks, can begin, while also relying on separate ETL pipelines, crawlers, and indexing infrastructure to locate and manage data. These approaches can add operational complexity and often provide limited support for file-based workflows. Qumulo removes these limitations by providing: