
Co-authored by: Bryan Berezdivin & Marcos Seoane
Enterprises across every industry are racing to adopt generative AI and foundation models (FMs). Even with massive investments in accelerated infrastructure, a persistent challenge remains, data and compute are rarely in the same place. Modern foundation models demand unprecedented scale. Training an FM can require thousands of GPU-accelerated instances running for days to weeks, consuming datasets that range from hundreds of terabytes for language models to tens of petabytes for multimodal systems combining text, imagery, and video. These datasets are not static and they evolve continuously as organizations retrain and fine-tune models to capture new edge cases, user feedback, or domain-specific data.
The reality for most large enterprises is that their data lives in on-premises data centers and across multiple clouds. This disconnect between data locality and accelerated compute availability has become one of the largest barriers to scaling artificial intelligence (AI). Moving petabyte-scale datasets across regions or clouds adds operational overhead, cost, latency, and governance complexity, directly impacting time-to-train and return of investment (ROI). A unified, locality-aware data fabric closes this gap. Qumulo’s unified data platform ensures global consistency, universal access, and low-latency access across multi-region or hybrid topologies, enabling a new data architecture paradigm that aligns with modern AI factories.
In this post, we outline the architectural elements of such a unified data platform, one capable of supporting large-scale AI workloads like foundation model training. We also show how Amazon SageMaker HyperPod, paired with Cloud Native Qumulo (CNQ), provides an end-to-end environment for distributed AI/ML training. SageMaker HyperPod delivers resilient orchestration and scaling of GPU clusters, while CNQ with Cloud Data Fabric (CDF) ensures that data is accessible, with low latency, across regions or sites. We illustrate verified reference architectures combining SageMaker HyperPod with CNQ in a single region (see Figure 1) and multi-region (see Figure 2) deployment, along with integration details for Qumulo and SageMaker HyperPod.
By pairing Qumulo with SageMaker HyperPod (and other cloud or on-premises AI tooling), organizations can:
- Accelerate time to results from pre- and post-training by >25%.
- Deploy AI workloads across your geo-distributed data and overcome accelerated compute scarcity.
- Reduce operational overhead for the AI data loop with zero orchestration
- Unify data governance and security policies across environments.
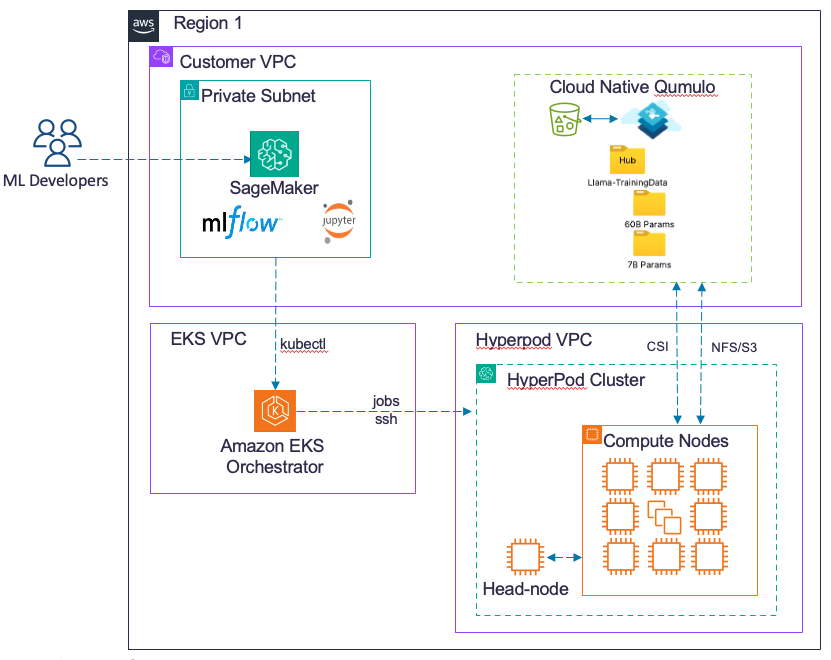
A Unified Data Platform for Foundation Model Training
Below are the key elements for the supporting foundation model training using data locally or data that is distributed geographically:
- High-throughput, low-latency access to data for sustained GPU utilization locally and remotely.
- Elastic scalability to handle multi-petabyte datasets and dynamically sized compute clusters.
- Multiprotocol support to provide optimal file-based libraries like PyTorch
- Global visibility and governance to meet data residency and compliance requirements.
Qumulo delivers each of these functions with its unique run-anywhere architecture that allows the unique features to manifest across any mix of compute, memory, and storage. This enabled the data platform to operate with best-in-class costs and performance in the cloud (AWS, Azure, GCP, and OCI) as well as on any server hardware on-premises including from HPE, Cisco, Penguin and others. This is the foundation of a unified platform, but just as important as the is the Qumulo multiprotocol support for applications to access and govern the data across these locations. This makes for easy integration across an enterprise application ecosystem, including various AI development toolchains like PyTorch, TensorFlow, and JAX. This also is key for enabling easy integration with Amazon SageMaker Hyperpod.
Guaranteeing high performance is key in expensive training runs, where Qumulo NeuralCache functionality delivers optimal performance in local and geo-distributed data architectures. As an example, average latencies were sub-millisecond for training llama-3.1-8B using multiple AWS P5e EC2 instances (each with 8 Nvidia H200 Tensor Core GPUs). We collected further performance data that will be posted separately for both single region and multi-region deployments.
For AI teams, developing models requires multiple training runs, which commonly use data outside of the site with accelerated compute resources. An example of this is the need to run a training run in region 1, but being delayed by days to even weeks due to GPU scarcity issues. The do-it-yourself (DIY) approach results in hundreds of pipelines to stage each preselected dataset for training and validation runs at an accelerated compute site. This results in delaying time to train, data sprawl, lack of consistency of datasets, and governance issues. An alternative approach is for a unified data platform to move the data on-demand on your behalf to ensure performance, cost efficiency, and consistency amongst sites. With Cloud Data Fabric (CDF), Qumulo provides a locality-aware data platform. CDF effectively extends a directory/prefix from a “hub” to one or multiple “spokes”. Spokes are fully coherent and use Neural Cache’s locality awareness and model ensemble to decide which data to prefetch for each workload. CDF enables spokes to provide applications with local performance as a result. We illustrate a verified architecture with SageMaker HyperPod and Qumulo in Figures 1 and 2.
This is effectively a new data paradigm for AI teams that will reduce engineer time to results and increase performance of new models by virtue of an optimized zero-orchestration data loop. Cost modeling shows that using this approach can drive down TCO by more than 30%. To achieve these goals, key features for a unified data platform with Qumulo are outlined below;
Elastic, High-Performance Data Access for Accelerated Compute
- Scale from 1 GB/s to 1 TB/s throughput with sub-millisecond latency as show in AI-Image benchmarks.
- Keep GPUs fully utilized by eliminating I/O stalls during data loading, sharding, checkpointing, or fine-tuning.
- Adapt automatically to each training workload using NeuralCache™ AI-driven caching and prefetching locally and remotely.
Unified Data Fabric for Workload Mobility
- Optimized latencies on spokes using NeuralCache™ AI-driven caching and prefetching seamlessly from the hub Qumulo clusters to/from multiple spoke Qumulo clusters.
- Compress, deduplicate, and WAN-optimize data transfers to cut data transferred by >30% as compared with manual copies.
- Apply consistent data across all environments with shared metadata, such as version information.
Multi-Protocol Flexibility
- Native support for S3, NFS, SMB, REST, and SFTP eliminates refactoring, re-architecting, or redundant copies..
- Data scientists, engineers, and simulation teams can access the same datasets with their preferred tools.
- Reduces data orchestration overhead by up to 4× versus traditional siloed storage.
SageMaker HyperPod with Qumulo
To demonstrate, Qumulo verified a common foundation-model workflow using SageMaker HyperPod deployed in the same region as the training data as well as deployed in a separate region from the training data set. The result is global model training without data duplication nor orchestration, but preserving consistency and reducing total cost of ownership. One key detail is that, in most AI model development efforts, we see only 30% of the labeled data used per training run, and significant overlap across the first and subsequent runs. This leads to higher ROI as compared to replicating your dataset per run, which is a common scenario for most teams in their orchestration efforts. Even more impactful to improving ROI is that many teams have built complex data catalogues to avoid redundancies for this purpose, which is no longer required to build, maintain, and evolve when Qumulo CDF is leveraged.
SageMaker HyperPod with Qumulo – Single-Region DataSet
In this deployment, we deployed CNQ with the training data in the same region with SageMaker HyperPod. CNQ was deployed in a single availability-zone approach that was not collocated with the P5e EC2 nodes. The architecture is shown in Figure 1.
SageMaker HyperPod with Qumulo – Multi-Region DataSet
In this deployment, we deployed CNQ in region 2 as the hub and region 1 as a spoke. CDF would optimally distribute data to/from the CNQ Spoke folder. This allows only the data needed for training to be distributed to the spoke.
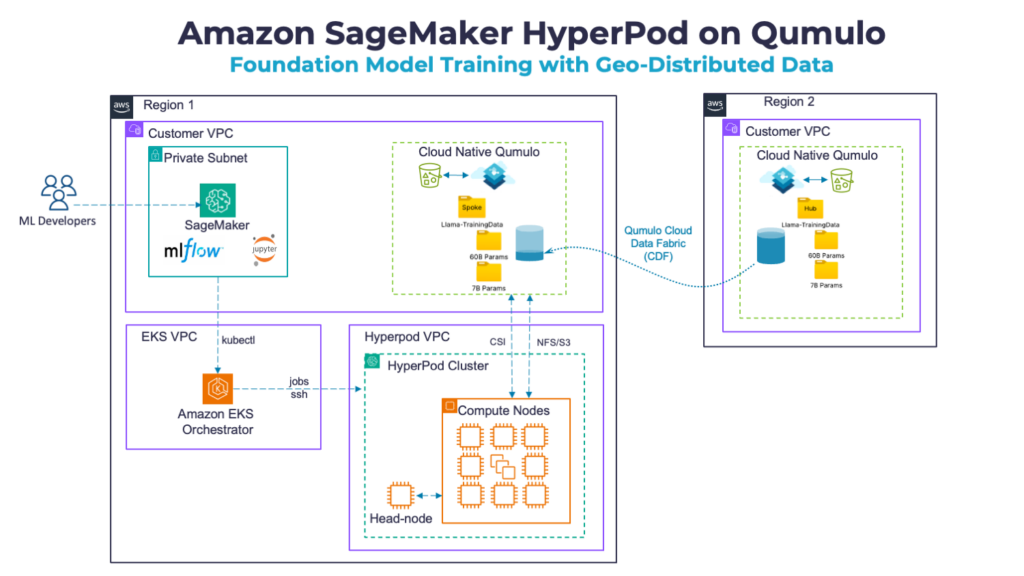
SageMaker HyperPod with Qumulo – Hybrid or Multi-Cloud Option
Many enterprises already operate GPU clusters in one environment while their datasets remain on another. Qumulo’s Cloud Data Fabric enables seamless hybrid or multicloud topologies with no orchestration needed:
- On-Prem to Cloud: Train on SageMaker HyperPod or Azure AI Foundry using on-prem Qumulo clusters as the authoritative data source. We illustrate this in Figure 2.
- Multicloud: Use Qumulo instances across AWS, Azure, and GCP with unified namespace and policy controls.
- Edge to Core: Collect, curate, and train on edge-generated data—without complex replication jobs.

Integrating Qumulo with SageMaker HyperPod
We provide below a verified recipe for a single region deployment using Cloud Native Qumulo (CNQ) on AWS marketplace to integrate with SageMaker Hyperpod. In this recipe CNQ supports the training data and checkpoints as well as use the NFS CSI driver to enable dynamic container deployments on SageMaker Hyperpod.
To reproduce a validated configuration, we outline the following steps;
Step 1: Provision Amazon EKS & HyperPod Cluster
We followed the EKS & HyperPod Setup Guide to deploy an EKS cluster and integrate SageMaker HyperPod.
# Create EKS Cluster with managed node groups
eksctl create cluster \
--name hyperpod-eks \
--version 1.29 \
--region us-west-2 \
--nodegroup-name workers \
--node-type P5.4xlarge \
--nodes 2 \
--nodes-min 2 \
--nodes-max 8
# Confirm nodes are ready
kubectl get nodes
Step 2: Deploy Qumulo Cluster via Terraform
Deploying Cloud Native Qumulo (CNQ) on AWS with Terraform involves setting up a fully elastic file data platform that leverages AWS S3 for persistent storage and EC2 instances for compute and cache resources. The deployment process follows the AWS Well-Architected Framework, ensuring scalability, security, and operational efficiency. Before beginning, the environment must meet several prerequisites, including proper IAM permissions, outbound internet connectivity to Qumulo’s endpoints, and the setup of an S3 VPC gateway if used. The Terraform deployment package provides modular templates that automate the provisioning of all required AWS resources.
The deployment occurs in two primary phases. First, persistent storage is established by creating the S3 buckets that will hold Qumulo data using Terraform configurations. Once storage is created, the second phase deploys the EC2 instances that host Qumulo Core. Terraform handles configuration consistency, naming conventions, and dependency management automatically, tagging all resources with a unique deployment identifier to avoid conflicts across multiple clusters.
After deployment, post-deployment tasks include validating the cluster configuration, confirming successful provisioning through AWS Systems Manager, and optionally setting up DNS resolution using Qumulo Authoritative DNS. The result is a fully operational, cloud-native Qumulo cluster capable of managing petabyte-scale data with the elasticity, multi-protocol access for S3, NFS, SMB, FTP and RestAPI access and integration benefits of AWS.
Follow the Guide to deploy CNQ on AWS using Terraform for detailed steps.
Step 3: Create Qumulo User & NFS Export
Using the Qumulo GUI Tool (accessible via http browser):
- Added a new user and permissions.
- Create an NFS export path /ai-factory-data.
Reference: How to Create an NFS Export.
Step 4: Install CSI Driver and Configure PVCs
To connect Kubernetes workloads to Qumulo, we installed the CSI driver and defined PVCs.
# Install Qumulo CSI Driver
helm repo add csi-driver-nfs https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/charts
helm install csi-driver-nfs csi-driver-nfs/csi-driver-nfs --namespace kube-system --version 4.12.0
# Example PV configuration
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-qumulo-static
spec:
capacity:
storage: 50Ti
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: ""
mountOptions:
- vers=3
- proto=tcp
- nolock
csi:
driver: nfs.csi.k8s.io
# Unique ID for this directory/volume; use a stable path-based handle volumeHandle: qumulo-nfs-root
volumeAttributes:
server: qumulo.qumulo-hub.com
share: "/csi"
# Example PVC configuration
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-qumulo-static
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Ti
storageClassName: ""
volumeName: pv-qumulo-static
Reference: Connecting Kubernetes with CSI Driver.
Step 5: Run the Workload
We deployed a Llama 2 model using PyTorch FSDP on Kubernetes.
# Launch distributed Llama 2 job with FSDP
kubectl create -f llama2-fsdp-job.yaml
Configuration followed the AWS sample: Llama 2 FSDP Example.
This setup is production-ready, validated for both single-region and multi-region operations, and forms the blueprint for hybrid and multi-cloud AI factories.
Conclusion
As enterprises scale their AI ambitions, the ability to train where compute is available without having to move to where data lives improves operational efficiencies and overall time to results for lines of business. Qumulo on-premises, in the cloud, and at the edge is an enabler to achieving this in the most cost-optimized manner with the performance and simplicity required for foundation-model development. By pairing Qumulo with SageMaker HyperPod (and other cloud or on-prem AI development frameworks), organizations can:
- Accelerate time to results from pre- and post-training by >25%.
- Deploy AI workloads across your geo-distributed data and overcome accelerated compute scarcity.
- Reduce operational overhead for the AI data loop with zero orchestration
- Unify data governance and security policies across environments.
Whether your GPUs run in AWS, Azure, GCP, or on-premises, Qumulo enables a train-anywhere, manage-everywhere AI strategy.
Learn more at qumulo.com/ai

