
Just over a decade ago, standing up a 100 terabyte cluster felt like a big deal. And at the time, it kind of was, considering what it took to manage that much storage back then. Today, a 100 terabytes might feel like a drop in the bucket. Many of you are now operating at multi-petabyte scale and increasingly looking to expand your deployments not just in your core data centers, but in multiple clouds, and at the edge. With new innovations coming out faster than you can plan for, and a steady stream of new data coming at you all the time, just trying to keep up can sometimes feel daunting.
New apps, workloads, and operating models are likely taking your data into new environments, at greater scale. Deploying, scaling, and moving data now needs to be made simple in any environment, for any workflow, from any device. After all, what good are all these new innovations if you’re too busy fire-fighting to even get around to using them? Well, that’s what we’re here for.
Refresh hardware with no migration
One of our newest capabilities may help you breathe a big sigh of relief. Say goodbye to those painful, tedious, and expensive lift-and-shift migrations that come with every new hardware refresh. Qumulo’s new Transparent Platform Refresh (TPR) capability now lets you swap out old hardware for new, without your end users even noticing. Now, you can finally retire those end-of-life nodes and refresh your platform with shiny new hardware without the headache of migrating data.
Platform refreshes with Qumulo are now as simple as: set a plan, add new nodes, remove old nodes, and you’re done! Your data effortlessly “glides” over to your new appliances. You can choose to refresh all your nodes at once, or a few at a time. You can also swap between nodes of different performance classes and different vendors to address any recent changes in workload performance or data-density requirements. This entire operation is unnoticeable to your end users so there’s no need to schedule downtime or sacrifice your weekend for the project.
Reclaim storage as you scale
Another capability we recently released will help you maximize your storage investment even more by helping you reclaim usable space as you add more nodes. While Qumulo has always used erasure coding to protect your data against disk or node failures, you were previously unable to adjust your cluster’s existing EC settings as capacity grew. Our new Adaptive Data Protection (ADP) capability allows you to adjust your EC settings to be more space-efficient as you add capacity to your cluster. This is particularly beneficial for customers with deployments that started small and grew significantly over time.
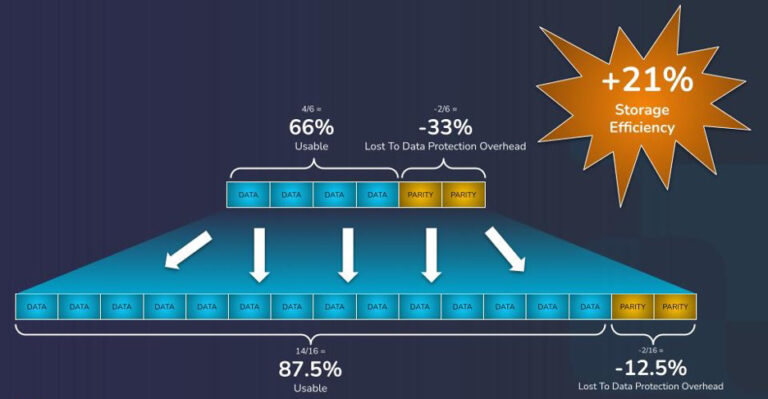
In the example above, the customer may have started with a small deployment, with only a limited number of nodes to spread their erasure coding stripe across. With the ratio of parity blocks needed to maintain fault tolerance for this cluster, they’re left with only 66% of their total storage as usable space. After growing their cluster over time, this customer could now use our ADP feature to adjust their EC configuration to a new, more efficient ratio. The cluster would still be protected against multiple concurrent disk or node failures, and the customer would have effectively expanded their cluster’s usable capacity by 21%!
Now certified to run on the highly performant HPE Alletra 4110 data storage server
Greater efficiency and a simpler hardware refresh process aren’t the only new capabilities we’re announcing, however. If you’re looking for scalable, high-performance storage to power your most intensive workloads, you can now use the all-flash, HPE Alletra 4110 data storage server. Purpose-built to power even the most demanding workloads like AI/ML, the HPE Alletra 4110 data storage server gives you the perfect balance of speed, space-efficiency, and security to realize the full value of your data, with minimal complexity and management overhead.
The HPE Alletra 4110 data storage server is the first product we’ve certified that leverages Enterprise and Data Center Standard Form Factor (EDSFF), the latest NVMe form-factor that also offers greater data density and thermal-efficiency. This helps you optimize your data center footprint and future-proof your storage investment while supporting the needs of your high-performance workloads today.
Running out of headroom on your existing cluster? Contact us to see if there’s usable storage you can unlock just by adding a new node.

