Qumulo accelerates GPU-side performance by eliminating load times between the object layer and the file system, achieving sub-millisecond latency and high throughput. Download the solution brief to learn more.
Qumulo accelerates GPU-side performance by eliminating load times between the object layer and the file system, achieving sub-millisecond latency and high throughput. Download the solution brief to learn more.
~90%
of all data that is unstructured.
28%
of the data that is powering AI models that is unstructured
31%
of enterprises say that a lack of production-ready pipelines holds AI plans back
There are three common storage challenges associated with AI data storage.
Data and AI Ecosystems are disconnected
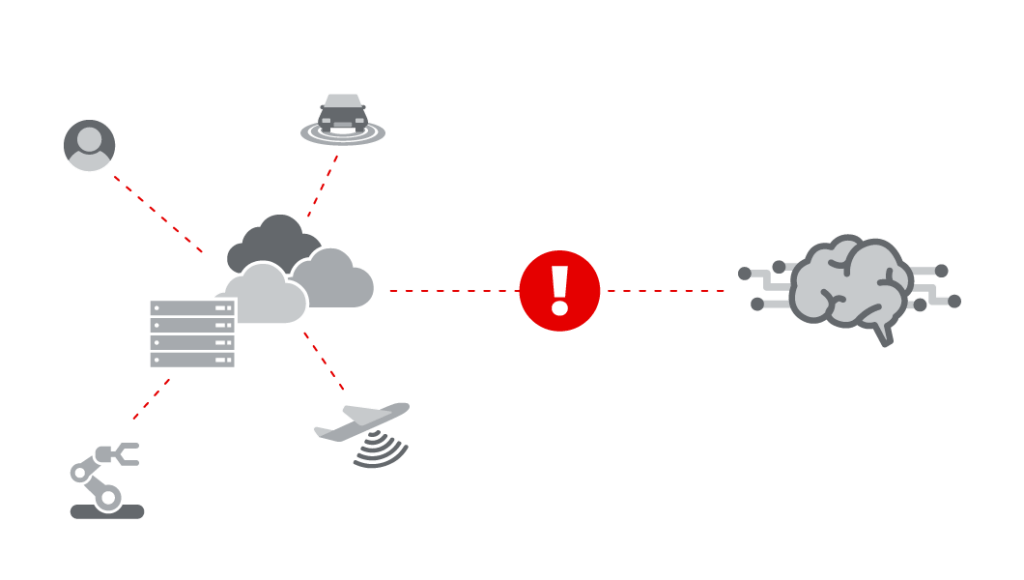
The data used for AI is generated at the edge or in the data center. Think IoT data coming from factory floors or from self-driving cars. But, the AI ecosystem lives in the cloud (AI services, expert consultations, etc.).
Enterprises must find a way to put that valuable data in proximity to their AI ecosystem in the cloud.
Placing all your AI unstructured data is difficult today
First, it is wildly expensive. Second, any apps that rely on that data need to be re-platformed to work with object data, as that is the only real option in the cloud today. This needs to change for AI to take off.
Legacy solutions throttle AI engines
Modern GPU-based massive parallel thread AI workflows can easily generate tens of thousands of concurrent reads, but many legacy solutions limit concurrent reads to a fraction of that. This throttles model-building.
This needs to be fixed for AI to become highly agile.
How Qumulo enables AI
We built Qumulo to blow up these obstacles. Here’s how . . .
Full-throttle, no excuses, concurrent reads
Qumulo has never placed limits on how many simultaneous reads you can perform. So unleash the hottest new Nvidia GPU tools and models away, free of limits from your file data platform.
Run Anywhere with Qumulo
Qumulo’s Run Anywhereplatform runs in the edge, core, and cloud. And, since Qumulo is a 100% software-only solution, you can run the hardware of your choice or in the cloud you want. Connect all your data everywhere to the latest cloud-based analytics engines with Qumulo Cloud Data Fabric.
Keep your data highly secure
Data breaches can lead to severe legal, financial, and reputational consequences. Protect all your data with Qumulo’s built-in data encryption and cryptographically-locked snapshots.
Connect Azure Native Qumulo to Microsoft Copilot
Did you know that Microsoft Copilot and Amazon Q can connect directly to your Cloud Native Qumulo deployment to read and analyze your Office files, PDF files, text files, and more? With Qumulo’s custom connectors, you can use Amazon Q or Copilot to gain to gain new intelligence and insight into virtually any type of unstructured data in your Azure Native Qumulo environment.
We built Qumulo to blow up these obstacles. Here’s how . . .
Modern Manufacturing
Factory floor cameras placed everywhere capture all manner of information in real-time automated manufacturing operations. All of this is aggregated continuously on local storage. For advanced objectives (e.g., automated failure detection), operations combine data from all manufacturing lines to become the source for training models. As the models mature, they are pushed back down to each factory to optimize operations.
Autonomous Vehicles
Self-driving vehicles continuously capture high-definition, multi-spectrum video of the real world. This begins with hundreds of test vehicles, then thousands of experimental vehicles, and finally with millions of regular vehicles. The cars upload these videos to a central location to train the models to assist drivers, enable autopilot, and make self-driving cars a reality. Inference models derived from the above are pushed back down to production vehicles. Then, the models process real-time data to optimize autonomous driving.
AI-assisted cyber-security
Network SecOps professionals consolidate activity logs from hundreds of thousands of network devices (from cloud, on-premises, or both). This forms the training data set for models to detect unauthorized network intrusions. The resulting inference models are pushed down into modern network devices, which analyze real-time observed events to spot unauthorized intrusions.