Technische Übersicht
Erfahren Sie, wie die einzigartige Cloud-native Architektur von Qumulo unstrukturierte Datendienste für alle Ihre Workloads bereitstellt, ob vor Ort, am Edge oder in der öffentlichen Cloud.
Inhaltsverzeichnis
Inhaltsverzeichnis
Überall ausführen
Datendienste und Speicherverwaltung
- Systemmanagement
- Web-Benutzeroberfläche
- Befehlszeilenschnittstelle
- REST API
- Qumulo-Nexus
- Zugriffsverwaltung
- Datensicherheitsfunktionen
- Active Directory
- Over-the-Wire-Verschlüsselung
- Datensicherheitsfunktionen
- Authentifizierung und Zugriffskontrolle
- Verwaltungssicherheit
- Admin-Benutzer auf Domänenebene
- Lokale Admin-Benutzer
- Single-Sign-On mit Multi-Faktor-Authentifizierung
- Zugriffstoken
- Rollenbasierte Zugriffssteuerung
- Verwaltungssicherheit
- Datenzugriffsverwaltung
- Zugriffssteuerungslisten
- Kerberos-Verbesserungen
- Unterstützung für Multiprotokoll-Berechtigungen
- Objektzugriffsberechtigungen
- Verkehrsbeschränkungen verwalten
- Zugriffssteuerungslisten
Datendienste
- Snapshots
- Snapshot-Sperre
- Quoten
- Zugriffsprotokollierung und -prüfung
- Eindringlingserkennung
- System- und Datenanalyse
- Replikation
- Kontinuierliche Replikation
- Snapshot-basierte Replikation
Das Qumulo-Dateisystem
- Dateisystemoperationen
- Skalierbarkeit des Dateisystems
- Metadatenaggregation
- Globaler Qumulo-Namespace
Der skalierbare Blockspeicher
- Globales Transaktionssystem
- Intelligentes Caching und Prefetching
- Physische Einsätze
- Geschützte virtuelle Blöcke
- Softwarebasierte Verschlüsselung im Ruhezustand
- Cloudbasierte Bereitstellungen
Server-Hardware
Diese Ressource herunterladen
Überall ausführen, überall skalieren
Mit Qumulos Cloud Data Fabric können Sie Ihre Anwendungen problemlos in jeder Umgebung, an jedem Ort und auf jeder Plattform erweitern oder integrieren. Es bietet die einzige global einheitliche, plattformunabhängige Lösung für unstrukturierte Daten, die alle Ihre Enterprise-, Hybrid-Cloud- und Multi-Cloud-Workflows unterstützt. Qumulos skalierbares Dateisystem und die leistungsstarken WebUI- und CLI-Tools vereinfachen die Datenverwaltung – egal, ob Sie sie für Ihre anspruchsvollsten Workflows oder als kostengünstige Cloud-Archivspeicherung benötigen. Unsere einzigartige, Cloud-native Architektur befreit Sie von Plattform- und Ortsbeschränkungen und ermöglicht Ihnen den Zugriff auf Daten von überall, ob in Ihrem Rechenzentrum oder in der Cloud.
Unser Ziel bei Qumulo ist es, die Speicherung unstrukturierter Daten für moderne Unternehmen einfach, skalierbar und global zu gestalten. Wir machen es einfach, Ihre Daten zu sichern. Wir machen es einfach, Ihre anspruchsvollsten Workflows auszuführen, ob vor Ort oder in der Cloud. Wir machen Hybrid-Cloud-Speicher einfach.
Die Softwarearchitektur von Qumulo
Wir haben unsere Speicherplattform zu einem Cloud-fähigen, skalierbaren Service entwickelt, der jeden dateibasierten Workflow überall unterstützen kann. Wir haben eine global erweiterbare Plattform aufgebaut. Wir bieten außerdem robuste APIs für automatisiertes Management und Echtzeit-Einblicke in die System- und Datennutzung. Unsere Speicherlösungen erfüllen die Sicherheits- und Datenschutzanforderungen von Fortune 500-Unternehmen.
Diese Seite bietet einen Überblick über die Architektur, Komponenten und Dienste der unstrukturierten Datenlösung von Qumulo. Sie zeigt, wie unser Produkt eine breite Palette von Anwendungsfällen unterstützt, von Medien und Unterhaltung bis hin zu Gesundheitswesen und Biowissenschaften, von Cloud-basiertem Hochleistungs-Computing bis hin zu kostengünstiger langfristiger Cloud-Archivspeicherung. Wir zeigen auch, wie unser einzigartiges Cloud Data Fabric kritische Daten über Plattformen, Standorte und Clouds hinweg vereinheitlichen kann, um Echtzeitzugriff auf Remote-Daten zu ermöglichen, die Zusammenarbeit zwischen weit verteilten Teams zu optimieren und die Geschäftsentwicklung in praktisch jeder Branche zu beschleunigen.
Qumulo-Architektur
Die modulare Architektur von Qumulo kann in eine Reihe von Schichten abstrahiert werden, wobei in jeder Schicht spezifische Servicekontrollen und Funktionen gebündelt sind. Diese Schichten arbeiten zusammen, um die Skalierbarkeit, Leistung, Sicherheit und Zuverlässigkeit der unstrukturierten Daten auf einer Qumulo-Instanz sowie des Qumulo-Systems selbst zu unterstützen.
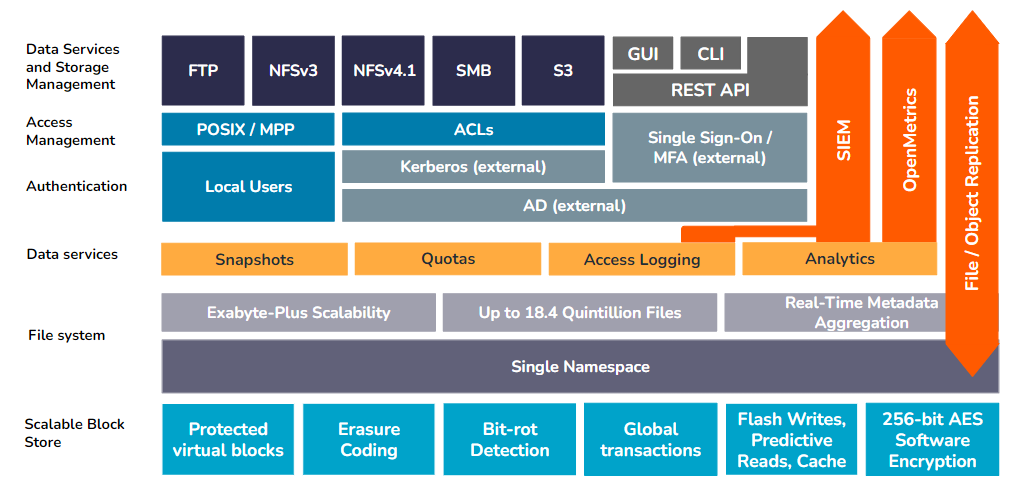
Qumulo-Grundlagen
Bevor wir uns mit den einzelnen Komponenten der Qumulo-Architektur befassen, sollten wir einige grundlegende Prinzipien aufzählen:
- Qumulo bietet ein 100 % softwaredefiniertes verteiltes Dateisystem, das einen einzigen Namespace darstellt. Ein lokaler Qumulo-Cluster besteht aus einer Shared-Nothing-Aggregation unabhängiger Knoten, wobei jeder Knoten zur Gesamtkapazität und Leistung des Clusters beiträgt. Einzelne Knoten bleiben in ständiger Koordination miteinander. Jeder Client kann sich mit jedem Knoten verbinden und im gesamten Namespace lesen und schreiben.
- Cloudbasierte Qumulo-Instanzen verwenden Objektspeicher (entweder AWS S3 oder Microsoft Azure Blob Storage, je nachdem, wo sie bereitgestellt werden) für die Datenebene, in der die mit einer bestimmten Datei verknüpften Blöcke abstrahiert und auf eine logische Sammlung diskreter Objekte verteilt werden.
- Diese Cloud-native Architektur eliminiert die herkömmliche Beziehung zwischen Rechenleistung, Speicherung und Durchsatz und schafft einen vollständig elastischen Dateispeicherdienst, der die Kapazität auf Hunderte von Petabyte und den Durchsatz auf über 100 GB/s skalieren kann.
- Dank der vollständigen Trennung von Rechenleistung und Speicher, die Qumulos Cloud-native-Architektur ermöglicht, haben Kunden die Flexibilität, die spezifischen Durchsatz- und Kapazitätsstufen, die sie benötigen, unabhängig voneinander auszuwählen. Ein Kunde kann sogar eine Qumulo-Instanz mit einem anfänglich geringen Rechenbedarf bereitstellen, dann die Rechenleistung des Dienstes vorübergehend skalieren, um den Durchsatz für einen kurzen Zeitraum drastisch zu erhöhen, und ihn anschließend wieder herunterskalieren, ohne zu irgendeinem Zeitpunkt zusätzliche Kapazität bereitstellen zu müssen.
- Qumulo ist auf Skalierbarkeit ausgelegt. Wir stellen sicher, dass alle Aspekte unseres Produkts problemlos Petabyte bis Exabyte an Daten, Billionen von Dateien, Millionen von Vorgängen und Tausende von Benutzern an Dutzenden von Standorten, Regionen und Bereitstellungen unterstützen können.
- Qumulo ist für die geografische Verteilung ausgelegt und ermöglicht es weit verteilten Teams, an gemeinsamen Datensätzen zusammenzuarbeiten, ohne dass das Risiko einer Datenbeschädigung oder eines Datenverlusts besteht.
- Qumulo optimiert sich selbst für maximale Leistung. Jede Qumulo-Instanz verfolgt den Datenzugriff mithilfe einer Heatmap, um häufig aufgerufene Datenblöcke zu identifizieren. Diese Blöcke werden proaktiv durch einen internen Prefetch-Algorithmus verschoben: Datenblöcke auf Langzeitspeichermedien werden in den Flash-Speicher verschoben, wenn ihr Heat-Score steigt. Wenn der Heat-Score weiter steigt, werden Daten, die sich bereits im Flash-Speicher befinden, proaktiv in den Systemspeicher verschoben, um noch schneller darauf zugreifen zu können. Auf globaler Ebene beträgt die Cache-Trefferquote über alle Qumulo-Instanzen für alle Qumulo-Kunden hinweg ~95 % aller Leseanfragen.
- Qumulo ist hochverfügbar und streng konsistent. Es ist so konzipiert, dass es Komponentenausfällen in der Infrastruktur standhält und den Kunden dennoch einen zuverlässigen Service bietet. Dies erreichen wir durch den Einsatz von Softwareabstraktion, Erasure Coding, fortschrittlichen Netzwerktechnologien und strengen Tests. Wenn Daten in das Dateisystem von Qumulo geschrieben werden, wird der Schreibvorgang dem Dienst, Benutzer oder Client erst bestätigt, wenn die Daten in den dauerhaften Speicher geschrieben wurden. Daher führt jede nachfolgende Leseanforderung zu einer kohärenten Ansicht der Daten (im Gegensatz zu letztendlich konsistenten Modellen).
- Qumulo bietet plattformunabhängige Dateidienste für die öffentliche, private und hybride Cloud. Die Software von Qumulo macht kaum Annahmen über die Plattform, auf der sie läuft. Es abstrahiert die zugrunde liegenden physischen oder virtuellen Hardwareressourcen, um die beste öffentliche und private Cloud-Infrastruktur zu nutzen. Dies ermöglicht es uns, die schnellen Innovationen bei Rechen-, Netzwerk- und Speichertechnologien zu nutzen, die von den Cloud-Anbietern und dem Ökosystem der Komponentenhersteller vorangetrieben werden.
- Das Qumulo-Verwaltungsmodell ist API-first. Jede von Qumulo erstellte Funktion wird zunächst als API-Endpunkt entwickelt. Anschließend präsentieren wir einen kuratierten Satz dieser Endpunkte in unserer Befehlszeilenschnittstelle (CLI) und der WebUI, unserer visuellen Schnittstelle. Dazu gehören Systemerstellung, Datenverwaltung, Leistungs- und Kapazitätsanalyse, Authentifizierung und Datenzugänglichkeit.
- Qumulo liefert schnell und regelmäßig neue Software. Wir veröffentlichen alle paar Wochen neue Versionen unserer Software. Dies ermöglicht es uns, schnell auf Kundenfeedback zu reagieren, die kontinuierliche Verbesserung unseres Produkts voranzutreiben und von unseren Teams auf Code in Produktionsqualität zu bestehen.
- Die containerbasierte Architektur von Qumulo ermöglicht einen einzigartigen Upgrade-Prozess, der Störungen für Benutzer und Arbeitsabläufe minimiert. Die neue Betriebssoftware wird fortlaufend, Knoten für Knoten, in einem parallelen Container zur alten Version bereitgestellt. Sobald die neue Instanz initialisiert wurde, wird die alte Umgebung ordnungsgemäß heruntergefahren und das Upgrade wird mit dem nächsten Knoten fortgesetzt, bis der gesamte Cluster aktualisiert wurde.
- Das Customer Success Team von Qumulo ist äußerst reaktionsschnell, vernetzt und flexibel. Qumulo kann jede Qumulo-Bereitstellung über unseren Cloud-basierten Mission Qontrol-Dienst aus der Ferne überwachen, wodurch wir Speicher- und Service-Telemetrie passiv verfolgen können (wir können keine Dateisystemdaten von Qumulo-Kundenbereitstellungen anzeigen oder darauf zugreifen). Unser Customer Success Team verwendet diese Daten, um Kunden bei Vorfällen zu helfen, Einblicke in die Produktnutzung zu geben und Kunden zu benachrichtigen, wenn in ihren Systemen Komponentenausfälle auftreten. Diese Kombination aus intelligentem Support und schneller Produktinnovation ermöglicht einen branchenführenden NPS-Score von über 80.
Das Qumulo-Dateisystem
Alle unstrukturierten Daten, die auf einem Qumulo-Dateisystem gespeichert sind, werden in einem einzigen Namespace organisiert. Dieser Namespace ist POSIX-kompatibel, um NFS3-Clients zu unterstützen, und unterstützt gleichzeitig den Access Control List-Standard, der von den Protokollen NFSv4.1 und SMB verwendet wird.
Qumulo zeichnet sich durch mehrere wichtige Funktionen aus: die Fähigkeit, einen einzelnen Namespace auf praktisch jede Größe zu skalieren, die nahtlose Integration von System- und Datenanalysen in Dateisystemoperationen, die Unterstützung für S3 und traditionelle Protokolle wie NFS und SMB sowie seinen innovativen Ansatz zur Verwaltung von Multiprotokollberechtigungen.
Dateisystemoperationen
Das Dateisystem von Qumulo wurde von Anfang an so konzipiert, dass es sich nahtlos auf eine Kapazität von über Exabyte in einem einzigen Namespace skalieren lässt, der Billionen von Dateien hosten kann, die über Standardprotokolle NFS und SMB gemeinsam genutzt werden können. Darüber hinaus wurde das Dateisystem so konzipiert, dass es Dateisystemaktualisierungen und -aktionen effizient überwachen und metadatenbasierte Statistiken und Vorgänge aggregieren kann. Dadurch sind Echtzeit-System- und Datenanalysen möglich, ohne dass ressourcenintensive, zeitaufwändige Tree Walks erforderlich sind.
Skalierbarkeit des Dateisystems
Eine einzelne Qumulo-Instanz kann auf eine Kapazität von Exabyte und 264 Knoten (~18.4 Trillionen Dateien) skaliert werden, ohne dass die bei anderen Plattformen üblichen Probleme auftreten, wie z. B. Inode-Erschöpfung, Leistungseinbußen und lange Wiederherstellungszeiten nach Komponentenausfällen.
Metadatenaggregation
Die einzigartige Architektur von Qumulo verfolgt Metadaten in Echtzeit, während Dateien und Verzeichnisse erstellt oder geändert werden. Verschiedene Metadatenfelder werden zusammengefasst, um einen virtuellen Index zu erstellen. Wenn Änderungen auftreten, werden neue aggregierte Metadaten gesammelt und von den einzelnen Dateien an die Wurzel des Dateisystems weitergegeben. Jeder Datei- und Verzeichnisvorgang wird berücksichtigt und die daraus resultierenden Änderungen werden sofort in die Analyse des Systems integriert. Die über das gesamte Dateisystem aggregierten Ergebnisse werden durch die integrierte Analyse-Engine von Qumulo sichtbar gemacht und bieten umsetzbare Datentransparenz, ohne dass teure Tree Walks durch die Dateidatenplattform erforderlich sind.
Der skalierbare Blockspeicher
Unter dem Qumulo-Dateisystem befindet sich eine geschützte, modulare Schicht, die als Schnittstelle zwischen potenziell Milliarden (oder mehr) von Dateien und Verzeichnissen und dem physischen Datenträger dient, auf dem sie gespeichert sind. In der modularen Architektur von Qumulo übernimmt die Scalable Block Store-Schicht diese Rolle.
Globales Transaktionssystem
Da Qumulo eine verteilte Shared-Nothing-Architektur verwendet, die sofortige Konsistenzgarantien bietet, muss jeder Knoten im Dienst jederzeit eine global konsistente Ansicht aller Daten haben. Der Scalable Block Store nutzt einen globalen Transaktionsansatz, um sicherzustellen, dass bei einem Schreibvorgang, der mehr als einen Block umfasst, entweder alle relevanten Blöcke geschrieben werden oder keiner davon. Für optimale Leistung maximiert das System Parallelität und verteiltes Rechnen und behält gleichzeitig die Transaktionskonsistenz von E/A-Vorgängen bei.
Dieser Ansatz minimiert den für transaktionale E/A-Vorgänge erforderlichen Sperraufwand und ermöglicht die Skalierung jeder Qumulo-Bereitstellung auf viele Hundert Knoten.
NeuralCache und intelligentes Prefetching
Die Software von Qumulo umfasst eine Reihe inhärenter Funktionen und konfigurierbarer Kontrollen, die alle darauf ausgelegt sind, die Daten im Cluster zu schützen.
- Alle Metadaten, die in jedem Datensatz am häufigsten gelesen werden, befinden sich dauerhaft auf der Flash-Ebene der Speicherinstanz.
- Häufig gelesene (gemessen durch einen proprietären „Hitzeindex“) virtuelle Blöcke werden auf Flash gespeichert, während selten gelesene virtuelle Blöcke auf kältere Medien verschoben werden, d. h. auf die HDD-Ebene des Systems (sofern verfügbar).
- Während Daten gelesen werden, überwacht die Qumulo-Instanz das Client-Verhalten und ruft neue Daten auf intelligente Weise vorab in den Systemspeicher auf dem Knoten ab, der dem Client am nächsten liegt, um die Zugriffszeiten zu beschleunigen.
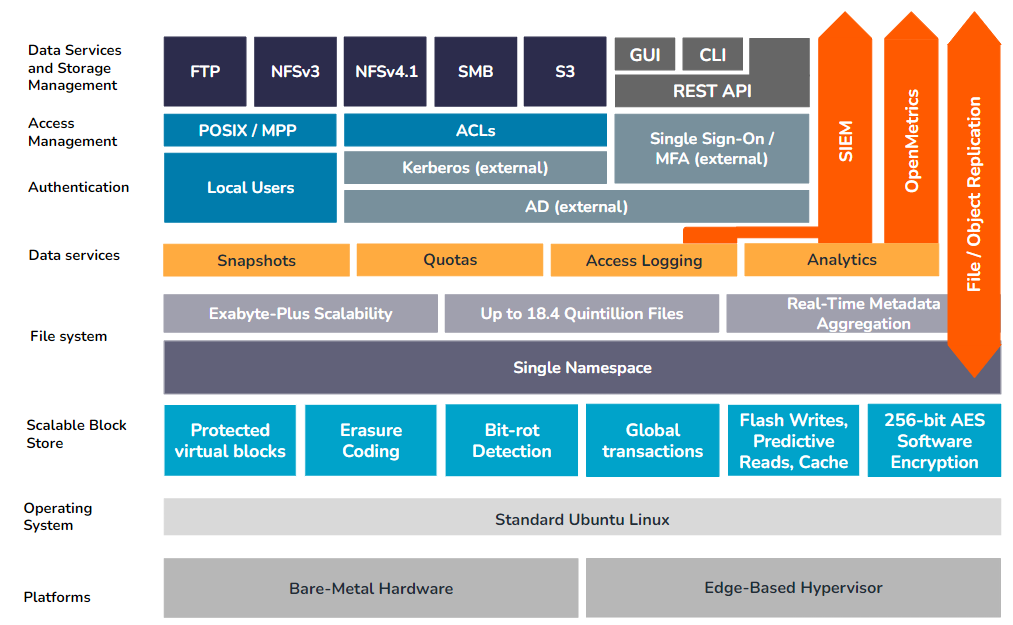
Physische Qumulo-Bereitstellungen (Cluster)
Auf einem physischen Qumulo-Cluster dient der Scalable Block Store als Schnittstelle zwischen dem Dateisystem und den zugrunde liegenden Speichermedien, bei denen es sich entweder um Solid-State-Flash-Geräte (SSDs) oder Festplattenlaufwerke (HDDs) handeln kann. Diese Schicht ist in erster Linie dafür verantwortlich, die Datenkonsistenz über alle Knoten in einem physischen Cluster hinweg zu gewährleisten, optimale Leistung für Lese- und Schreibanforderungen sicherzustellen und Datensicherheit, Integrität und Widerstandsfähigkeit gegen Komponentenausfälle zu gewährleisten.
Geschützte virtuelle Blöcke
Die Speicherkapazität eines physischen Qumulo-Clusters ist konzeptionell in einem geschützten virtuellen Adressraum organisiert. Jede Adresse innerhalb dieses Raums speichert entweder einen 4K-Datenblock oder einen 4K-Erasure-Coding-Hash, mit dem alle durch Hardwarefehler verlorenen Datenblöcke wiederhergestellt werden können. Das Verhältnis von Datenblöcken zu Erasure-Coding-Blöcken wird durch die Größe des physischen Clusters bestimmt – wenn weitere Knoten hinzugefügt werden, passt sich das Verhältnis an, um eine höhere Gesamteffizienz zu bieten und gleichzeitig vor Festplatten- und Knotenausfällen zu schützen.
Zusätzlich zum Schutz durch Erasure Coding umfasst das virtuelle Blocksystem auch einen Bit-Rot-Erkennungsalgorithmus zum Schutz vor Datenbeschädigung auf der Festplatte.
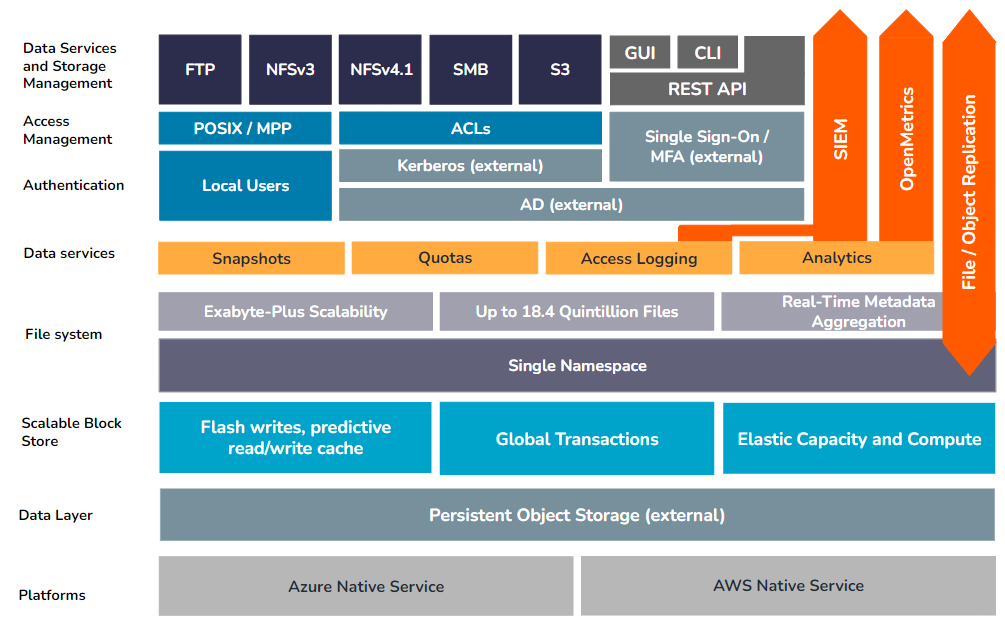
Cloudbasierte Qumulo-Instanzen
Für auf Azure bereitgestellte Qumulo-Instanzen werden viele der Funktionen, die lokal von der Scalable Block Storage-Schicht bereitgestellt werden, wie z. B. Festplattenverschlüsselung, Erasure Coding, Bit-Rot-Erkennung und Blockverwaltung, als Kernfunktionen der zugrunde liegenden Azure bereitgestellt Blob-Speicherdienst.
Verschlüsselung in Ruhe
Auf physischen Qumulo-Clustern enthält der Scalable Block Store einen softwarebasierten AES-256-Bit-Algorithmus, der alle Dateisystemdaten verschlüsselt, bevor er sie in die Datenschicht schreibt. Dieser Algorithmus wird im Rahmen des anfänglichen Cluster-Erstellungsprozesses initialisiert und umfasst alle Dateisystemdaten und Metadaten auf Blockebene für die gesamte Lebensdauer des Clusters.
Qumulo-Cluster in der Cloud basieren auf Blockverschlüsselung auf der zugrunde liegenden Objektspeicherebene, die vom Cloud-Dienstanbieter implementiert und verwaltet wird. Dadurch wird sichergestellt, dass alle ruhenden Daten auf jeder Cloud-basierten Qumulo-Instanz vollständig verschlüsselt sind.
Für Unternehmen, die es benötigen, ist der integrierte Qumulo-Verschlüsselungsalgorithmus, der in jedem physischen Cluster verwendet wird, mit den FIPS 140-2-Standards kompatibel, ebenso wie die von Azure und AWS Object Storage bereitgestellten Verschlüsselungsdienste.
Datendienste
Die Data Services-Schicht umfasst fünf Verwaltungsfunktionen: Snapshots, Replikation, Kontingente, Zugriffsprotokollierung und -prüfung sowie System- und Datenanalyse.
Snapshots
Snapshots auf einem Qumulo-Cluster können auf verschiedene Arten verwendet werden, um die Daten des Clusters zu schützen:
- Sie können lokal für eine schnelle und effiziente Datensicherung und -wiederherstellung eingesetzt werden.
- Ein Snapshot der Live-Daten auf einem Qumulo-Cluster kann auf eine sekundäre Qumulo-Instanz repliziert werden, beispielsweise eine Azure Native Qumulo Cold-Dienstinstanz, die im Falle eines Systemausfalls am primären Standort ein sofortiges Failover der Dateidatendienste unterstützen könnte .
- Qumulo-Snapshots können auch mit Backup-Software von Drittanbietern kombiniert werden, um einen wirksamen langfristigen Schutz (mit robusterer Versionskontrolle für geänderte Dateien) vor Datenverlust zu bieten.
Snapshot-Sperre
Um zusätzlichen Schutz vor Ransomware-Angriffen oder dem vorzeitigen Löschen kritischer Snapshots über ein kompromittiertes Administratorkonto zu bieten, können Snapshots kryptografisch „gesperrt“ werden, wodurch die Änderung oder vorzeitige Löschung eines Snapshots selbst durch einen Administrator verhindert wird.
Für die Verwendung gesperrter Snapshots ist ein asymmetrisches kryptografisches Schlüsselpaar erforderlich, wobei der öffentliche Schlüssel direkt auf der Qumulo-Instanz installiert und der private Schlüssel gemäß den etablierten Schlüsselverwaltungspraktiken der Organisation extern gespeichert wird.
Quoten
Mit Kontingenten können Benutzer das Wachstum jeder Teilmenge eines Qumulo-Namespace steuern. Kontingente fungieren als unabhängige Grenzen für die Größe jedes Verzeichnisses und verhindern ein Datenwachstum, wenn die Kapazitätsgrenze erreicht ist. Anders als bei anderen Plattformen und Diensten werden Qumulo-Kontingente sofort wirksam, sodass Administratoren mithilfe unserer Echtzeit-Kapazitätsanalyse unerwünschte Arbeitslasten identifizieren und eine außer Kontrolle geratene Kapazitätsauslastung sofort stoppen können. Kontingente folgen sogar dem Teil des Namespace, den sie abdecken, wenn Verzeichnisse verschoben oder umbenannt werden.
Zugriffsprotokollierung und -prüfung
Die Audit-Protokollierung bietet einen Mechanismus zur Verfolgung von Ereignissen und Verwaltungsvorgängen im Qumulo-Dateisystem. Wenn verbundene Clients Anfragen an den Cluster stellen, beschreiben Ereignisprotokollmeldungen jeden versuchten Vorgang. Diese Protokollmeldungen werden dann über das Netzwerk an eine bestimmte Remote-Syslog-Instanz gesendet, z. B. eine branchenübliche SIEM-Plattform (Security Information and Event Management) wie Splunk.
Erkennung von Eindringlingen und Ransomware in Echtzeit
Qumulo ist eine Partnerschaft mit den Drittanbietern Superna und Varonis eingegangen, um eine Echtzeitüberwachung von Ereignis- und Zugriffsprotokollen zu ermöglichen, um Cyberangriffe zu erkennen und darauf zu reagieren. Um mehr über Varonis mit unserer Azure Native Qumulo-Lösung zu erfahren, besuchen Sie unsere Varonis-Integration mit ANQ Seite. Informationen zu Superna Ransomware Defender sind verfügbar werden auf dieser Seite erläutert.
Replikation
Der integrierte Replikationsdienst von Qumulo kann Daten in großem Umfang zwischen zwei beliebigen Qumulo-Speicherinstanzen kopieren. Neben dem Schutz der Daten vor Cyberangriffen kann ein sekundärer Standort mit einem anderen Qumulo-Cluster auch als Failover-Speicher im Falle eines Ausfalls auf Site-Ebene dienen.
Da alle Qumulo-Instanzen dieselben Replikationsfunktionen unterstützen und unabhängig vom Standort dieselben Dienste bereitstellen, kann die Replikation so konfiguriert werden, dass sie in jede Richtung zwischen zwei beliebigen Qumulo-Endpunkten ausgeführt wird, egal ob vor Ort, in AWS oder auf Azure.
Kontinuierliche Replikation
Bei dieser Replikationsform wird einfach ein Snapshot der Daten auf dem Qumulo-Quellcluster erstellt und in ein Verzeichnis auf einem Zielcluster kopiert. Solange die Replikationsbeziehung aktiv ist, scannt das System alle geänderten Dateien, um nur die spezifischen Änderungen zu identifizieren und auf das Ziel zu kopieren. Dabei werden alle vorherigen Versionen der Daten überschrieben.
Snapshot-basierte Replikation
Bei der Snapshot-basierten Replikation werden auch Snapshots des Zielverzeichnisses auf dem sekundären Cluster erstellt. Sobald ein Replikationsauftrag abgeschlossen ist, wird ein neuer Snapshot des Zielverzeichnisses erstellt, der die Datenkonsistenz über beide Cluster hinweg gewährleistet und gleichzeitig ein Änderungsprotokoll und einen Versionsverlauf für jede Datei auf dem Ziel beibehält.
System- und Datenanalyse
Der Software-Stack von Qumulo ist so konzipiert, dass er in jeder Qumulo-Instanz Echtzeiteinblicke in System- und Servicemetriken, einschließlich Kapazität und Leistung, bietet. Dadurch können Kunden Fehler bei Anwendungen beheben, den Kapazitätsverbrauch verwalten und Erweiterungs- (oder Archivierungs-)Strategien planen. Die Analysen von Qumulo basieren auf der Aggregation von Metadatenänderungen im gesamten Dateisystem, sobald diese auftreten.
Die Weboberfläche umfasst Echtzeit-Überwachungstools zur Verfolgung der Systemleistung, der Kapazitätsnutzung und der aktuellen Aktivität auf der lokalen Qumulo-Instanz. Für Unternehmen, die diese Informationen in eine externe Überwachungslösung exportieren möchten, unterstützt Qumulo den OpenMetrics API-Standard zum Exportieren und Kompilieren von Syslog-Daten.
Instanz- und Datendienstverwaltung
Als branchenüblicher Dateidatenspeicherdienst unterstützt Qumulo alle unstrukturierten Datenzugriffsprotokolle: SMB, NFS und NFSv4.1. Es unterstützt auch den Objektzugriff mithilfe des S3-Protokollstandards. Qumulo unterstützt auch FTP- und REST-API-Zugriff auf ausgewählte Datentypen.
Systemmanagement
Jede Qumulo-Instanz, ob vor Ort oder in der Cloud, kann mit denselben Standardtools verwaltet werden: einer integrierten Web-Benutzeroberfläche für interaktive Speicherung und Datenverwaltung, einer CLI-basierten Befehlsbibliothek oder einem API-basierten Satz von Management-Tools.
Web-Benutzeroberfläche
Qumulo bietet eine browserbasierte Verwaltungsoberfläche, auf die von der Speicherinstanz selbst zugegriffen werden kann, ohne dass eine separate VM oder ein separater Dienst erforderlich ist. Die intuitive Web-Benutzeroberfläche ist in sechs Navigationsabschnitte auf oberster Ebene gegliedert: Dashboard, Analytics, Sharing, Cluster, API & Tools und Support.
Befehlszeilenschnittstelle (CLI)
Die Qumulo-CLI unterstützt den Großteil (aber nicht die gesamte) API-Bibliothek und ist auf die Systemadministration ausgerichtet. Die CLI bietet eine skriptfähige Interaktionsmethode für die Arbeit mit einer Qumulo-Instanz. Eine vollständige Liste der Befehle finden Sie in unserer Knowledge Base (care.qumulo.com).
REST API
Die REST-API ist eine Obermenge aller Funktionen der Qumulo-Datenplattform. Über die API können Administratoren:
- Erstellen Sie einen Namensraum
- Konfigurieren Sie alle Aspekte eines Systems (von der Sicherheit, wie Identitätsdienste und Systemverwaltungsrollen, bis hin zur Datenverwaltung und zum Schutz, einschließlich Kontingenten, Snapshot-Richtlinien und/oder Datenreplikation)
- Sammeln Sie Informationen über die Qumulo-Zielinstanz (einschließlich Kapazitätsauslastung und Leistungs-Hotspots).
- Zugriffsdaten (einschließlich Lese- und Schreibvorgänge)
- Die API ist „selbstdokumentierend“, sodass Entwickler und Administratoren jeden Endpunkt leicht erkunden können (und Beispielausgaben sehen). Qumulo pflegt eine Sammlung von Beispielverwendungen unserer API auf GitHub (https://qumulo.github.io/).
Qumulo-Nexus
Da Qumulo-Kunden zunehmend auf Multi-Cloud- und Multi-Site-Unternehmensabläufe umsteigen, müssen sie die Komplexität der Überwachung der Verfügbarkeit und Servicemetriken jeder Qumulo-Instanz über separate Verwaltungsoberflächen reduzieren. Mit Qumulo Nexus können Kunden die Überwachungsvorgänge für alle ihre Qumulo-Instanzen – ob vor Ort, am Rand oder in der Cloud – in einem einzigen Verwaltungsportal konsolidieren, das dieselben Echtzeitanalysen und Datentransparenz bietet wie die lokale Weboberfläche.
Sicherheit und Zugriffsverwaltung
Die Software von Qumulo umfasst mehrere integrierte Funktionen und konfigurierbare Steuerelemente, die alle darauf ausgelegt sind, den Zugriff auf die Daten im Cluster zu schützen.
Qumulo-Datensicherheitsfunktionen
Jede Qumulo-Instanz, ob vor Ort oder in der Cloud, nutzt ein Paar Kontrollen, die sicherstellen, dass alle Daten im Dateisystem auf Datenspeicherebene vor Beschädigung, Verlust oder Einbruch geschützt sind.
Active Directory-Integration
Das Sicherheitszugriffsmodell von Qumulo wurde so entwickelt, dass es Microsoft Active Directory (AD) sowohl für Administrator- als auch für Benutzerrechte und -berechtigungen nutzt. Neben den offensichtlichen Vorteilen einer einzigen Datenquelle für alle Benutzerkonten unterstützt die Verwendung von AD für die Verwaltung von Privilegien und Berechtigungen die branchenweit bewährtesten Praktiken in den folgenden Bereichen:
- Nahtlose Integration mit Kerberos-basierten Authentifizierungs- und Identitätsverwaltungsprotokollen
- Integration mit SSO- und MFA-Zugriffsanbietern
- Die Verwendung von Zugriffskontrolllisten-basierten Berechtigungen für SMB- und NFSv4.1-Clients zum Ablegen von Systemdaten
Over-the-Wire-Datenverschlüsselung
Selbst wenn die entsprechenden Sicherheitseinstellungen auf Freigabe- und Datenebene vorhanden sind, benötigen einige Unternehmen eine zusätzliche Datensicherheitsebene, um Daten vor unbefugtem Zugriff zu schützen. Für diese Umgebungen unterstützt Qumulo auch die drahtlose Datenverschlüsselung zu und von unterstützten Clients.
Für SMB3-Freigaben unterstützt Qumulo bei Bedarf sowohl clusterweite als auch freigabebezogene Verschlüsselung. NFSv4.1-Exporte, die eine erhöhte Sicherheit erfordern, können so konfiguriert werden, dass sie entweder krb5i-Paketsignaturen verwenden, die die Datenintegrität gewährleisten, oder krb5p-basierte Paketverschlüsselung, um ein Abfangen während der Übertragung zu verhindern.
Der gesamte objektbasierte Datenverkehr wird automatisch mit den standardmäßigen TLS-/HTTPS-Verschlüsselungsstandards verschlüsselt.
Authentifizierung und Zugriffskontrolle
Der Zugriff auf Daten im Qumulo-Dateisystem sowie der Zugriff auf das Qumulo-Speichersystem erfolgt über branchenübliche Authentifizierungs- und Zugriffsprotokolle und gewährleistet so eine Zugriffsverwaltung, Identitätskontrolle und Überprüfbarkeit auf Unternehmensniveau.
Verwaltungssicherheit
Rechte und Privilegien auf Systemebene werden basierend auf der Mitgliedschaft in einer oder mehreren lokalen Gruppen auf der einzelnen Qumulo-Instanz gewährt. Administratorrechte werden allen lokalen und Domänenkonten gewährt, die Mitglieder der integrierten Administratorengruppe des Clusters sind.
Administratoren auf Domänenebene
Die meisten Unternehmenssicherheitsrichtlinien erfordern, dass die Verwaltung und Verwaltung kritischer Unternehmenssysteme einer Ein-Benutzer- und Ein-Konto-Richtlinie folgt, um genaue Aufzeichnungen des Systemzugriffs und der Privilegiennutzung sicherzustellen. Die einfachste Methode zur Einhaltung dieser Richtlinie besteht darin, die relevanten Active Directory-Benutzerkonten zur lokalen Administratorengruppe des Clusters hinzuzufügen.
Lokale administrative Benutzer
Jede Qumulo-Instanz verfügt über ein Standardkonto namens Admin, dem automatisch die Mitgliedschaft in der lokalen Administratorgruppe zugewiesen wird und der über sämtliche Administratorrechte und -privilegien für den Cluster verfügt.
Single Sign-On mit Multi-Faktor-Authentifizierung
Single Sign-On (SSO) macht es für einen Administrator überflüssig, seine Anmeldeinformationen erneut einzugeben, um Zugriff auf das System zu erhalten. Unternehmen wünschen sich SSO nicht nur, weil es den Anmeldevorgang rationalisiert und die Authentifizierung für Administratoren bequemer macht, sondern auch, weil es das Risiko eines Kontodiebstahls durch Tastenanschlag-Logger oder des Abfangens verringert, wenn der Anmeldeversuch das Netzwerk durchquert.
Die Mehrfaktor-Authentifizierung (MFA) fügt dem Anmeldevorgang eine weitere Sicherheitsebene hinzu. Dabei müssen Administratoren einen Einmalcode von einem Schlüsseltoken oder einer Challenge-Anfrage auf einem separaten Gerät abrufen, das sich nicht im Besitz eines Eindringlings befinden darf.
Die SSO-Lösung von Qumulo lässt sich über Security Assertion Markup Language (SAML) 2.0 in Active Directory integrieren. Für MFA können Kunden jeden Identitätsanbieter (IdP) nutzen, der in die im Cluster registrierte AD-Domäne integriert ist, einschließlich, aber nicht beschränkt auf OneLogin, Okta, Duo und Azure AD.
Zugriffstoken
Um den Prozess der automatisierten Speicherung und Datenverwaltung über die API-Funktionalität von Qumulo zu vereinfachen, bietet Qumulo Administratoren die Möglichkeit, ein langlebiges API-Token zu generieren, das von automatisierten Workflows unbegrenzt verwendet werden kann, bis der Schlüssel entweder widerrufen oder gelöscht wird. Das Token wird von einem Administrator über die CLI generiert und kann an jeden API-basierten Workflow angehängt werden, der nun authentifizierte API-Aufrufe durchführen kann, ohne sich anmelden zu müssen.
Zu Prüfzwecken wird jedes Token einem bestimmten AD- oder Clusterkonto zugeordnet. Wenn das zugehörige Benutzerkonto gelöscht oder deaktiviert wird, funktioniert das Zugriffstoken nicht mehr.
Rollenbasierte Zugriffssteuerung
Mithilfe der rollenbasierten Zugriffskontrolle (RBAC) können Administratoren nicht-administrativen Benutzern oder Gruppen, die für bestimmte Verwaltungsaufgaben erhöhte Rechte für den Cluster benötigen, fein abgestufte Berechtigungen zuweisen. Die Verwendung des RBAC-Modells ermöglicht die sichere Delegation von Berechtigungen nach Bedarf, ohne dass vollständige Administratorrechte erteilt werden müssen. Unternehmen können damit auch die erforderlichen Systemberechtigungen erteilen und gleichzeitig eine überprüfbare Prüfspur für den Zugriff und die Verwendung von Berechtigungen sicherstellen.
Datenzugriffsverwaltung
Qumulo verwendet für die Verwaltung des Zugriffs auf Dateisystemdaten dasselbe Sicherheitsmodell und nutzt unternehmensübliche Standardverfahren, Protokolle und Tools, um den Zugriff auf alle Dateien und Verzeichnisse im System zu verwalten und zu verfolgen.
Zugriffssteuerungslisten
Für über SMB und NFSv4 gemeinsam genutzte Workloads unterstützt Qumulo die Authentifizierung über Active Directory und Zugriffssteuerungslisten (ACLs) im Windows-Stil, die über beide Protokolle hinweg gemeinsam genutzt werden können.
Kerberos-Verbesserungen
Alle SMB- und NFSv4.1-Datenanforderungen werden mithilfe der Kerberos-basierten Benutzeridentitätsverwaltung authentifiziert, wenn sie von einem Windows- oder Linux-Client stammen, der derselben Domäne wie der Qumulo-Cluster beigetreten ist (oder einer vertrauenswürdigen Domäne beigetreten ist).
Unterstützung für Multiprotokoll-Berechtigungen
Qumulo unterstützt die gleichzeitige Bereitstellung derselben Daten im Dateisystem über mehrere Protokolle. In vielen Fällen kann eine SMB-Freigabe im Cluster auch als NFSv3-Export, NFSv4.1-Export und Objektspeichercontainer konfiguriert werden. Während dies die Flexibilität des Clusters maximiert, müssen bei der Verwaltung von Berechtigungen einige Überlegungen berücksichtigt werden.
SMB und NFSv4.1 verwenden beide dasselbe ACL-basierte Berechtigungsmodell, bei dem dem Benutzer der Zugriff aufgrund der Mitgliedschaft des Active Directory-Kontos des Benutzers in einer oder mehreren Gruppen gewährt oder verweigert wird, deren Zugriff auf Datenebene konfiguriert wurde.
Bei gemischten SMB/NFSv3-Workloads kann es jedoch zu einer Nichtübereinstimmung zwischen den ACL-Berechtigungen einer bestimmten Datei oder eines Verzeichnisses und seinen POSIX-Einstellungen kommen. Eine Qumulo-Instanz kann für den Mixed-Mode-Betrieb konfiguriert werden, bei dem SMB- und POSIX-Berechtigungen für Dateien und Verzeichnisse, die von beiden Protokollen gemeinsam genutzt werden, separat verwaltet werden.
Für Workloads mit gemischten Protokollen behält das proprietäre Multiprotokoll-Berechtigungsmodell (MPP) von Qumulo SMB-ACLs und Vererbung bei, selbst wenn die NFS-Berechtigungen geändert werden.
Objektzugriffsberechtigungen
Wenn ein Verzeichnis im Cluster über das S3-Protokoll freigegeben wird, wird es als S3-Bucket behandelt und alle Unterverzeichnisse und Dateien in diesem Verzeichnis werden als Objekte innerhalb des Buckets behandelt.
Wenn ein Benutzer oder Workflow versucht, auf ein Objekt zuzugreifen, verwendet das System den vom Client bereitgestellten Zugriffsschlüssel, um die zugeordnete Active Directory- oder lokale Benutzer-ID des Schlüssels zu identifizieren, und vergleicht diese ID dann mit der SMB-/NFSv4.1-Zugriffskontrollliste des Objekts.
Verkehrsbeschränkungen verwalten
Zusätzlich zur Verwendung der SSO- und MFA-basierten Authentifizierung bestimmter Administratorkonten unterstützt Qumulo auch Sicherheitsrichtlinien, die die Einschränkung des Zugriffs auf Administratorebene auf speziell bestimmte Netzwerke oder VLANs erfordern, indem es die Möglichkeit bietet, bestimmte TCP-Ports auf individueller VLAN-Ebene zu blockieren.
Auf diese Weise kann eine Qumulo-Instanz so konfiguriert werden, dass sie Verwaltungsdatenverkehr – z. B. API, SSH, Web-UI und Replikationsdatenverkehr – vom Clientdatenverkehr, z. B. SMB, NFS und Objektzugriff, segmentiert.
Cloud-Datenstruktur
In einer vernetzten Multi-Cloud-Welt müssen geografisch verteilte Teams, Anwendungen und Teams die Möglichkeit haben, an gemeinsamen Datensätzen zusammenzuarbeiten, ohne die Latenz einer WAN-Verbindung oder die lange Wartezeit für die Replikation von Daten im großen Maßstab zwischen Standorten in Kauf nehmen zu müssen.
Qumulos Cloud Data Fabric (CDF) erweitert Qumulos skalierbares Dateisystem auf zwei oder mehr Qumulo-Instanzen und ermöglicht es geografisch verteilten Teams und Workflows, einen einzigen Datensatz in Echtzeit gemeinsam zu nutzen. CDF bietet nicht nur latenzarmen Zugriff auf kritische Daten zwischen Qumulo-Instanzen vor Ort, am Edge und in der Cloud, sondern macht in vielen Fällen auch die groß angelegte Replikation in gemeinsam genutzten Workflows vollständig überflüssig.
CDF vereinheitlicht einen oder mehrere gemeinsam genutzte Datensätze über Standorte, Clouds, Plattformen und Regionen hinweg und stellt Daten Teams, Anwendungen und Organisationen zur Verfügung, die in Echtzeit zusammenarbeiten müssen. Durch die Verwendung von CDF können Unternehmen den WAN-Verkehr minimieren und gleichzeitig die standortübergreifende Daten- und Sicherheitsverwaltung vereinfachen.
Global Namespace
Qumulos Cloud Data Fabric ermöglicht einen wirklich globalen Namespace, in dem kritische Datensätze zwischen Qumulo-Instanzen überall geteilt werden: im Rechenzentrum, in der Cloud und am Rand. Qumulos globaler Namespace verwendet einzigartige innovative Funktionen, die in ihrer Kombination Datentransparenz in Echtzeit und weltweite Zusammenarbeit an gemeinsam genutzten Daten ermöglichen.
Metadatensynchronisierung
Anstatt Datei- und Ordnerdaten sofort über alle Instanzen hinweg zu synchronisieren, die einen bestimmten Datensatz gemeinsam nutzen, repliziert die Global Namespace-Implementierung von Qumulo zunächst nur die Metadaten zwischen den Qumulo-Endpunkten, sodass Remote-Clients die gesamte Datei- und Ordnerstruktur von Remote-Datensätzen mit nur wenigen Millisekunden Verzögerung sehen können.
Verteilte Sperrung
Um die Datenintegrität in einer verteilten Umgebung sicherzustellen, in der jede Datei von jedem Benutzer oder jeder Anwendung an mehreren Standorten geändert werden kann, verwendet CDF einen Sperralgorithmus, der den Dateizugriff über alle Endpunkte hinweg koordiniert. Dadurch wird sichergestellt, dass jede Datentransaktion autorisiert und protokolliert wird und strikt mit allen vorherigen Aktionen übereinstimmt.
Datensicherheit
Durch die Replikation von Dateisystemmetadaten zwischen Endpunkten werden auch die ACLs (SMB und NFSv4.1) und POSIX-Berechtigungen repliziert. Wenn alle Benutzer im Portal dieselbe Authentifizierungsquelle verwenden, wird der Datenzugriff automatisch zwischen den Endpunkten übertragen.
Wenn ein Portal gelöscht wird, werden die Links zu allen Spoke-Endpunkten beendet und alle lokal zwischengespeicherten Daten werden von jedem Spoke gelöscht. Sofern die zugrunde liegende Freigabe oder der Export nicht ebenfalls gelöscht wird, verbleiben die Daten auf der Qumulo-Instanz, die als Hub-Endpunkt diente.
Datenportale
Der einzigartige Ansatz von Cloud Data Fabric für einheitlichen Datenzugriff basiert auf Datenportalen. Portale werden auf der Ebene der einzelnen SMB-Freigaben oder NFS-Exports veröffentlicht (oder auf beiden, da Qumulo auch Multiprotokoll-Datenfreigabe bietet). Durch die Erstellung eines CDF-Portals werden die Daten innerhalb dieser Freigabe oder dieses Exports einer oder mehreren zusätzlichen Qumulo-Instanzen zur Verfügung gestellt.
CDF-Portale können sowohl schreibgeschützte als auch bidirektionale Anwendungsfälle unterstützen.
Portalendpunkte
Cloud Data Fabric-Portale werden mithilfe einer Hub-and-Spoke-Topologie erstellt, in der eine Qumulo-Instanz (der „Hub“) als maßgeblicher Eigentümer der Portaldaten fungiert und alle Datenzugriffsvorgänge über alle Portalendpunkte hinweg koordiniert. Jedes Portal verfügt über einen einzelnen Hub mit einem oder mehreren „Spoke“-Endpunkten, die als Erweiterungen des Namespace des Portals fungieren.
Um ein neues Portal zu erstellen, identifiziert ein Administrator die spezifische Freigabe oder den Export auf dem Hub, der veröffentlicht werden soll, weist mindestens einen zusätzlichen Qumulo-Endpunkt als Spoke zu und bezeichnet das neue Portal als schreibgeschützt oder bidirektional. Zusätzliche Qumulo-Instanzen können dem Portal nach Bedarf als Spokes hinzugefügt werden.
Jeder Endpunkt in einem CDF-Portal kann auch als unabhängige Qumulo-Speicherinstanz fungieren und zusätzliche Freigaben und/oder Exporte hosten, deren Verwendung ausschließlich auf lokale Clients beschränkt ist.
Journalisierte Protokollierung
Alle Dateisystemvorgänge innerhalb eines bestimmten Portals werden über einen verteilten Protokollierungsmechanismus verfolgt. Jedes Datenzugriffsereignis (Erstellen, Lesen, Ändern, Löschen usw.) wird im gemeinsamen Protokoll aufgezeichnet und auf alle anderen Endpunkte im Portal repliziert.
Logische Zeiterfassung
Die Verwendung eines gemeinsamen logischen Zeitversatzes zur Koordinierung von Ereignissen über Endpunkte hinweg anstelle eines absoluten physischen Zeitstempels stellt sicher, dass Datentransaktionen in der richtigen Reihenfolge über alle Knoten in allen Endpunkten hinweg angewendet werden, ohne dass Zeitzonenunterschiede oder Zeitversätze zwischen den verschiedenen Qumulo-Instanzen ausgeglichen werden müssen.
Logische Protokollierung und Wiederherstellung
Wenn ein Portal-Spoke die Verbindung zum Hub verliert, sind Portaldaten für die Clients dieses Spokes nicht mehr verfügbar. An den übrigen Endpunkten des Portals werden in der verteilten Protokolldatei weiterhin Änderungen an Daten innerhalb des Portals verfolgt.
Bei der Wiederherstellung der Verbindung gibt der betroffene Spoke die Ereignisse im Protokoll in der richtigen Reihenfolge wieder, um seine lokal zwischengespeicherten Daten mit den übrigen Endpunkten im Portal abzugleichen.
Transferoptimierung
Cloud Data Fabric wurde entwickelt, um die begrenzte Bandbreite optimal zu nutzen und selbst in weit verteilten Unternehmen leistungsstarken Zugriff auf Remote-Daten mit geringer Latenzzeit in großem Maßstab zu ermöglichen. Dies wird erreicht, indem darauf gewartet wird, dass Clients die spezifischen Portaldaten anfordern, die sie benötigen. Nur relevante Daten werden lokal auf jedem Endpunkt zwischengespeichert und nur geänderte Datenblöcke zwischen Endpunkten repliziert, anstatt ganze Dateien oder ganze Datensätze.
Lokales Caching
Der erste Zugriff auf Daten von einem Remote-Endpunkt führt dazu, dass die angeforderte Datei oder der angeforderte Ordner über das Netzwerk „gezogen“ und auf dem lokalen Qumulo-Endpunkt zwischengespeichert wird. Vorausgesetzt, dass sich die Daten nach dem ersten Zugriff nicht ändern, werden alle nachfolgenden Zugriffsanforderungen für dieselben Daten aus dem lokalen Cache bedient.
Sparse-Dateisysteme
Jeder Spoke erstellt ein Schattendateisystem, unabhängig von allen anderen Dateidaten, die er lokal hostet. Es enthält die Metadaten des Portals sowie alle lokal zwischengespeicherten Portaldaten. Die lokale Instanz verwendet eine Heatmap, die dem intelligenten Caching-System ähnelt, aber davon unabhängig ist, das die Leseleistung für das lokale Dateisystem optimiert, um die Häufigkeit zu überwachen, mit der auf zwischengespeicherte Daten zugegriffen wird.
Die Größe dieses Sparse-Dateisystems variiert mit der verfügbaren Speicherkapazität der jeweiligen Qumulo-Instanz. Wenn neue Portaldaten angefordert werden und das Sparse-Dateisystem voll wird, werden ältere Daten aus dem Cache gelöscht, um eine optimale Leistung für neu eingehende Daten zu gewährleisten.
Prädiktive Zwischenspeicherung
Während lokale Clients und Anwendungen auf Dateien und Ordner zugreifen, überwacht jeder Endpunkt, welche Portaldaten im Laufe der Zeit passiv zum Sparse-Dateisystem-Cache hinzugefügt werden, und beginnt, Muster im Client- und Anwendungsverhalten zu erkennen. CDF verwendet diese Zugriffsmuster, um vorherzusehen, welche Datenblöcke wahrscheinlich als nächstes angefordert werden, und lädt diese Blöcke präventiv in den Sparse-Dateisystem-Cache, bevor sie angefordert werden.
Server-Hardware
Die Software von Qumulo läuft auf praktisch jeder standardmäßigen x86-64-basierten Hardware der Enterprise-Klasse. Kunden, die optimale Verfügbarkeit und Leistung wünschen, sollten sich jedoch direkt mit Qumulo in Verbindung setzen, bevor sie die geeignete Hardwarekonfiguration auswählen.
Das zugrunde liegende Linux-Betriebssystem ist gesperrt und erlaubt nur die Vorgänge, die zur Ausführung der erforderlichen unterstützenden Aufgaben der Qumulo-Softwareumgebung erforderlich sind. Andere Standard-Linux-Dienste wurden deaktiviert, um die Angriffsfläche für einen Angriff weiter zu verringern.
Vollständig nativer Software-Stack
Obwohl Linux Open-Source-Komponenten enthält, um sowohl NFS- als auch SMB-Client- und Serverdienste (z. B. Samba, Ganesha usw.) bereitzustellen, sind diese Dienste nicht im gehärteten Ubuntu-Image enthalten, das die Qumulo-Softwareumgebung unterstützt. Qumulo entwickelt und steuert den gesamten Code, der für die Datenzugriffsprotokolle NFS, SMB, FTP und S3 verwendet wird – in der Qumulo-Betriebsumgebung.
Sofortige Upgrades
Der iterative Entwicklungsprozess von Qumulo ist einfach und rationalisiert, und es werden regelmäßig neue Software-Updates veröffentlicht. Dies ermöglicht schnelle Innovationen zur Entwicklung und Einführung neuer Funktionen und fördert eine sicherere Speicherplattform.
Qumulo hat den Upgrade-Prozess so konzipiert, dass er schnell und einfach abläuft. Der Qumulo Core-Software-Stack ist vollständig containerisiert und ermöglicht das Upgrade eines gesamten Clusters in 20 Sekunden, unabhängig von der Größe. Rollbacks sind nicht mehr erforderlich, da die Funktionalität und Stabilität der aktualisierten Version vollständig validiert werden kann, bevor die ältere Version abgeschaltet wird.