
Qumulo nativo de la nube escaló a 1.6 TB/s en AWS, y eso no es lo mejor. Esto es lo que significa para ti.
Durante años, los clientes empresariales han expresado la misma preocupación sobre la nube:
“Simplemente no es lo suficientemente rápido”.
“Incluso si así fuera, no podríamos obtener de manera confiable suficiente capacidad computacional en una zona de disponibilidad”.
Un cliente explicó el desafío claramente:
“Necesitamos superar los 1.5 TB/s de rendimiento sostenido en la nube, sin sacrificar la confiabilidad ni la flexibilidad”.
Esa "B" mayúscula de TB importa. Se trata de bytes, no de bits. Un byte equivale a ocho bits, por lo que 1.5 TB/s se traducen en aproximadamente 12 terabits por segundo de movimiento sostenido de datos. Y el movimiento sostenido es igual de importante. No se trata de una ráfaga breve ni de un pico de caché, sino de un rendimiento continuo que se mantiene a lo largo del tiempo.
Para poner esa cifra en contexto, la transmisión de una sola película 4K suele requerir unos 25 megabits por segundo. A 12 Tb/s, el mismo sistema podría, en teoría, soportar casi... medio millon transmisiones 4K simultáneas.
Y para aquellos que se lo preguntan, Qumulo CNQ estuvo a la altura del desafío, alcanzando 1.6 TB/s y 20.7 millones de IOPS, pero hablaremos más sobre eso más adelante.
De hecho, las cifras de rendimiento por sí solas nunca fueron la verdadera preocupación. Pocas empresas necesitan 1.5 TB/s hoy en día, pero la experiencia nos dice que planificar solo para la demanda actual rara vez da buenos resultados. Desarrollar sistemas de alto rendimiento a partir de recursos en la nube suele ser una cuestión de presupuesto, tolerancia al riesgo y fragilidad del sistema. De hecho, desarrollar solo para la velocidad es una excelente manera de familiarizarse con el director financiero de muchas organizaciones, aunque no de forma positiva. Combinar la velocidad con una arquitectura de infraestructura frágil puede resolver temporalmente un desafío, pero genera muchos desafíos tecnológicos y económicos adicionales como consecuencia.
Para resolver el problema de raíz de la flexibilidad arquitectónica es necesario un nuevo pensamiento.
La mayoría de las plataformas de almacenamiento en la nube obligan a los clientes a tomar decisiones anticipadas sobre la infraestructura a largo plazo. El rendimiento, la disponibilidad y el coste están estrechamente vinculados, lo que requiere un sobreaprovisionamiento para los picos de demanda, la duplicación de datos para garantizar la resiliencia o la fijación de cargas de trabajo a ubicaciones específicas. Una vez tomadas estas decisiones, es difícil y costoso revertirlas.
Como resultado, el almacenamiento se convierte en la restricción que los equipos de cómputo toman en cuenta para planificar, en lugar de una base flexible que se adapte a las cargas de trabajo cambiantes.
La mejor pregunta que deberían hacerse los clientes no es: "¿Qué tan rápido puede ir esto?"
La pregunta es la siguiente: ¿puede la nube brindarme un rendimiento extremo cuando lo necesito, sin limitarme a arquitecturas frágiles, almacenamiento duplicado o infraestructura con exceso de aprovisionamiento permanente?
Qumulo se tomó ese desafío en serio. No persiguiendo una cifra destacada, sino probando un modelo operativo diferente. Y es por eso que 1.6 TB/s NO ES EL TITULAR. Podrías preguntarte: "Qumulo, si escalado a 1.6 TB/s en AWS, “¿No es el titular? ¿Qué es?”
¿Qué pasaría si el verdadero titular no fuera sobre la velocidad en absoluto, sino sobre la eliminación de las restricciones zonales sin pagar un impuesto económico?
La respuesta comienza con una arquitectura nativa de la nube, no una modernizada.
Creado para la nube desde el principio
La arquitectura de Qumulo fue diseñada para la nube, no adaptada a ella. Esa distinción es importante.
La mayoría de los sistemas de almacenamiento de archivos en la nube no fallaron por una ejecución deficiente. Fallaron porque heredaron las premisas de una era definida por el hardware y nunca se rediseñaron completamente para las operaciones en la nube.
Los sistemas de archivos tradicionales se basaban en una simple verdad física: el hardware de almacenamiento definía tanto la capacidad como el rendimiento. Más discos significaban más espacio, y más espacio significaba mayor rendimiento. La capacidad y el rendimiento estaban físicamente acoplados. No era posible escalar significativamente uno sin el otro. Ese modelo era perfectamente lógico cuando las organizaciones adquirían discos giratorios, instalaban servidores en rack y cableaban sus propias redes.
Cuando los proveedores de nube introdujeron servicios de archivos administrados, muchas de esas mismas suposiciones se mantuvieron vigentes.
Algunos servicios escalan la capacidad automáticamente, pero el rendimiento sigue estando ligado a la cantidad de datos almacenados. Otros requieren que los clientes aprovisionen capacidad y rendimiento conjuntamente como atributos fijos. La elasticidad existe, pero está limitada por la misma combinación que existía en las instalaciones.
Como el rendimiento y la capacidad siguen vinculados, los clientes se quedan con dos opciones poco atractivas:
- Previsión de horas punta: Pague por el máximo rendimiento y capacidad en todo momento, incluso cuando la utilización sea baja
- Provisión para media: Ahorrar dinero hasta que las cargas de trabajo se topan con un muro y el rendimiento se convierte en el cuello de botella
La mayoría de los equipos eligen la primera opción porque el costo de las cargas de trabajo limitadas o los plazos incumplidos supera con creces el costo del exceso de aprovisionamiento; sin embargo, pagar por lo que se puede La necesidad es lo opuesto a la economía de la nube.
El problema se agrava cuando entra en juego la diversidad de protocolos. Los entornos Linux requieren NFS. Los entornos Windows requieren SMB. Las aplicaciones modernas dependen cada vez más del acceso a objetos mediante API compatibles con S3.
El resultado es la fragmentación. Diferentes servicios, diferentes modelos de escalado, diferentes comportamientos operativos. Los equipos que ejecutan cargas de trabajo mixtas suelen gestionar múltiples sistemas de almacenamiento, cada uno optimizado para un caso de uso específico.
Con el tiempo, el almacenamiento se convierte en la limitación que los equipos informáticos deben tener en cuenta para planificar.
"¿Cuánto almacenamiento tenemos?", preguntan, "¿Qué podemos ejecutar?"
Esto es al revés. La infraestructura debería adaptarse a las cargas de trabajo, no al revés.
Cloud Native Qumulo rompe ese acoplamiento.
Desde su inicio, CNQ separó el rendimiento de la capacidad por diseño. El cómputo escala independientemente del almacenamiento de objetos duradero, y el rendimiento se incrementa o se reduce ajustando los recursos computacionales en lugar de preasignar capacidad. Los clientes solo pagan por el almacenamiento que consumen, mientras que el rendimiento se convierte en un atributo flexible en lugar de un compromiso fijo.
Esto permite a CNQ respaldar servicios de archivos empresariales de propósito general de manera económica mientras escala a cargas de trabajo especializadas y de alta intensidad sin obligar a los clientes a un aprovisionamiento excesivo permanente o a silos de almacenamiento fragmentados.
Esto deja claro el titular: CNQ diseñado para la nube, no adaptado a ella. Aún así, siento que falta algo.
El desafío: ir más rápido que en las instalaciones, sin red de seguridad
El requerimiento del cliente no era teórico.
En las instalaciones, la carga de trabajo se ejecutaba en un único centro de datos, con los recursos de computación ubicados cerca del almacenamiento para minimizar la latencia. Si fallaba la infraestructura, ya sea de energía, refrigeración o red, la carga de trabajo se detenía. Existía la recuperación ante desastres, pero, como la mayoría de los sistemas de recuperación ante desastres, era asincrónica, estaba sometida a pruebas limitadas y no podía mantener el rendimiento completo de la carga de trabajo.
El sistema funcionaba, pero era frágil.
Tradicionalmente, migrar a la nube nunca se ha tratado de velocidad. Se trataba de eliminar puntos únicos de fallo sin introducir nuevas restricciones. Pero si pudiera ser rápido, ¿cómo afectaría eso a los negocios de nuestros clientes?
En la nube, las expectativas eran claras:
- Superar el rendimiento local
- Evite la dependencia de una única zona de disponibilidad
- Mantener el rendimiento completo durante fallas
- Hazlo sin duplicar los costos de almacenamiento
Este último requisito es donde muchos sistemas de archivos en la nube fallan.
La mayoría de las ofertas multizona de disponibilidad utilizan replicación. Se mantienen copias completas de los datos en cada zona para garantizar la disponibilidad. Si bien este enfoque es eficaz para la durabilidad, conlleva consecuencias reales. Los costos de almacenamiento aumentan linealmente con el número de zonas. El rendimiento de escritura se reduce debido a la coordinación entre zonas. Multi-AZ se convierte en algo que los clientes reservan para escenarios de fallo en lugar de para el funcionamiento normal.
Al mismo tiempo, la disponibilidad computacional en la nube no está distribuida de manera uniforme.
Las cargas de trabajo con uso intensivo de GPU y CPU suelen enfrentarse a limitaciones de capacidad que varían según la zona y con el tiempo. Un diseño que ancla los datos a una sola zona obliga a que el cómputo se adapte, incluso cuando existe capacidad en otras partes de la región. Los clientes terminan buscando instancias, reservando el cómputo antes de que los datos estén listos (lo cual resulta costoso) o retrasando el trabajo por completo (lo que prolonga el tiempo de obtención de resultados).
El cliente retó a Qumulo con velocidad, confiabilidad y resiliencia. La solución debía ofrecer un mayor rendimiento, eliminando la dependencia a nivel de zona y la duplicación de almacenamiento, y permitiendo que las cargas de trabajo se ejecutaran dondequiera que hubiera capacidad de cómputo disponible en cualquier momento.
Qumulo resuelve ese problema a nivel arquitectónico, en lugar de superponer la disponibilidad sobre suposiciones heredadas.
La arquitectura: Zona de disponibilidad múltiple por diseño, no por duplicación
En el núcleo de esta implementación había un clúster CNQ multi-AZ, distribuido uniformemente en tres zonas de disponibilidad dentro de una sola región de AWS.
Una Zona de Disponibilidad (AZ) es un conjunto físicamente separado de uno o más centros de datos dentro de una región de AWS. Cada AZ está diseñada para operar de forma independiente, con su propia energía, refrigeración y red, y está conectada a otras AZ de la región mediante enlaces de alto ancho de banda y baja latencia. Esta separación permite que las aplicaciones permanezcan disponibles incluso si un centro de datos completo sufre una interrupción.
Amazon S3 proporciona durabilidad a nivel regional, donde los datos se protegen automáticamente en múltiples instalaciones. Por eso, AWS ofrece 11 nueves (99.999999999 %), ampliamente reconocido como el referente del sector en protección de datos.
Por diseño, la arquitectura de CNQ abarca múltiples zonas de disponibilidad de AWS sin requerir réplicas completas de los datos de los clientes en cada zona. Como resultado:
- El costo de almacenamiento es idéntico independientemente de si CNQ se ejecuta en una AZ o en varias AZ
- El rendimiento de escritura no se ve penalizado por la replicación entre zonas
- El funcionamiento Multi-AZ es el estado normal, no un modo de falla
Nota: Normalmente, los servicios multi-AZ cuestan el doble que sus implementaciones de una sola AZ. Mantener el mismo costo ofrece una importante ventaja económica.
Si una zona de disponibilidad deja de estar disponible, el clúster continúa funcionando en las zonas restantes sin pérdida de datos y sin necesidad de conmutar por error a una copia secundaria.
Este diseño es más simple, más rápido y materialmente más barato que los enfoques multi-AZ basados en réplicas.
Sería fácil hacer de este el titular: La arquitectura CNQ ofrece resiliencia multi-AZ sin duplicación de datos. No nos equivocamos. Pero podemos hacerlo aún mejor.
La ventaja de la zona de disponibilidad múltiple de CNQ para cargas de trabajo con uso intensivo de GPU
Multi-AZ suele considerarse una característica de disponibilidad, lo cual está bien, pero hoy en día, la disponibilidad se considera fundamental. Lo que realmente importa es lo que CNQ ofrece para la computación: simplificar la adquisición de GPU y CPU.
La mayoría de los sistemas de archivos en la nube, incluso los que se comercializan como multi-AZ, anclan el almacenamiento a una única zona principal. El cómputo debe seguir los datos. Si las GPU o CPU no están disponibles en esa zona, la carga de trabajo se detiene, incluso si hay capacidad sin usar en otra parte de la región.
Esto obliga a los equipos a buscar GPU y CPU. Primero, buscan instancias de cómputo escasas. Luego, reservan y pagan por ese cómputo antes de poder usarlo. A continuación, surge el problema de los datos. Grandes conjuntos de datos deben copiarse o reorganizarse dondequiera que se encuentre el cómputo. Solo después de completar todos estos pasos se puede reanudar el trabajo. CNQ elimina esta restricción.
Con CNQ, los recursos de computación en múltiples zonas de disponibilidad pueden acceder al mismo conjunto de datos simultáneamente. Los clientes pueden agregar capacidad de diferentes zonas en un único pool lógico sin tener que copiar ni reorganizar los datos.
Si las GPU están disponibles en una zona el lunes y en otra el martes, los clientes no transfieren datos ni reconstruyen la infraestructura. Simplemente dirigen la implementación de CNQ existente a donde haya capacidad de procesamiento disponible.
Desde la perspectiva del cliente, esto permite:
- Acceso más rápido a GPU y CPU escasas
- Sin fases de reorganización o copia de datos
- Sin penalizaciones por replicación
- Sin aumento en el costo de almacenamiento
El trabajo puede comenzar de inmediato, ya que los datos ya existen en cada zona de disponibilidad de S3, que funciona como capa de almacenamiento persistente. A diferencia de Amazon Elastic Block Store (EBS) o el almacenamiento conectado a instancias, esta arquitectura no requiere copiar ni rehidratar los datos en cada zona antes de que comience el procesamiento. En su lugar, el sistema de archivos accede a los datos localmente en cada zona de disponibilidad (AZ) a través de NeuralCache. Este enfoque elimina semanas de trabajo de almacenamiento de datos y mantiene los costosos recursos de procesamiento completamente utilizados desde el principio.
Una vez más, podrías estar pensando: seguramente este tiene que ser el titular: CNQ y el arte de hacer que la búsqueda de GPU sea soportable. Vamos por buen camino. A ver si podemos superarlo.
Aumente el rendimiento tanto como desee y luego redúzcalo
El cliente solicitó superar los 1.5 TB/s de rendimiento sostenido en la nube, sin sacrificar la fiabilidad ni la flexibilidad. Qumulo creó una implementación de prueba que superó las expectativas, alcanzando 1.6 TB/s de rendimiento agregado sostenido y 20.7 millones de IOPS. Sin duda, estas cifras son impresionantes (para futuros lectores, consulten la fecha de publicación para más información), pero ¿son requisitos máximos o promedio? Y si usted es cliente y está leyendo esto y le interesan los 1.6 TB/s y los 20.7 millones de IOPS, no se preocupe, ¡lo tenemos cubierto! Vea a continuación.
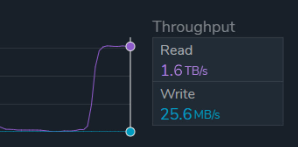
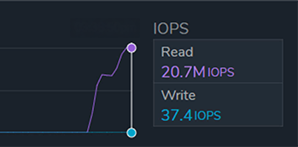
Muchos clientes priorizan la flexibilidad y necesitan la capacidad de escalar recursos según la demanda. Como se mencionó anteriormente, los clientes suelen elegir entre aprovisionar para picos de demanda a un alto costo o dimensionar para un uso promedio, arriesgándose a sufrir deficiencias de rendimiento. Esta disyuntiva resalta el valor fundamental de la nube: la variabilidad. Esta configuración puede costar aproximadamente $5,000 por hora, lo que la hace valiosa cuando se necesita, pero económicamente impráctica para operar de forma continua. La capacidad de consumir este nivel de rendimiento solo cuando se requiere hace que un enfoque basado en la nube sea económicamente viable en comparación con la infraestructura local.
CNQ permite a los clientes alcanzar el máximo rendimiento sin tener que pagar por la capacidad máxima constantemente. Esa es la diferencia.
En muchos sistemas de archivos en la nube, el rendimiento está ligado a la capacidad aprovisionada permanentemente. Si dimensiona para las horas punta, pagará el precio de hora punta constantemente, incluso cuando la carga de trabajo disminuya.
CNQ disocia esas decisiones.
Los clientes pueden ajustar el rendimiento de forma agresiva para cumplir con una fecha límite, una ventana de capacitación o un aumento repentino de la producción, y luego reducirlo una vez superado el pico. No se limita a una configuración de límite máximo solo para cubrir picos ocasionales.
Esta elasticidad se aplica no solo a la escala, sino también a la elección de instancias. En esta implementación, los tipos de instancias se ajustaron a mitad del diseño debido a las limitaciones de capacidad regional. El clúster simplemente creció a 250 nodos, manteniendo aproximadamente 333 000 conexiones, utilizando un menor ancho de banda por nodo sin necesidad de rediseño.
Más tarde, los clientes pueden realizar la transición a familias de instancias más nuevas a un menor costo mediante el reemplazo continuo, sin tiempo de inactividad ni migración de datos.
Juntos, finalmente hemos descubierto el titular: CNQ ofrece Máximo rendimiento sin máximo compromiso. ¿Verdad? Pero ¿por qué alguien necesitaría este nivel de rendimiento máximo?
Los momentos que exigen un rendimiento máximo extremo
No todas las cargas de trabajo necesitan un rendimiento extremo, y ese es precisamente el objetivo.
Esta arquitectura no se trata de funcionar siempre a 1.6 TB/s. Se trata de tener la opción de funcionar a esa velocidad cuando el tiempo apremia, sin verse perjudicado financiera ni operativamente el resto del tiempo.
Lo que hoy parece excesivo suele convertirse en la norma mañana. Entonces, ¿por qué alguien necesitaría este rendimiento?
Imaginemos una empresa energética que decide si arrendar un pozo de mil millones de dólares. La pregunta no es si el análisis cuesta unos millones más en inversión en la nube. La pregunta es quién llega primero a la respuesta. Ser precoz puede determinar quién asegura el activo y quién se marcha con las manos vacías.
En el ámbito sanitario, un análisis genómico más rápido puede marcar la diferencia entre una incertidumbre prolongada y una decisión de tratamiento que salve vidas.
En medios y entretenimiento, la velocidad puede determinar si un proyecto llega a su fecha de lanzamiento o si los retrasos se traducen en costos imprevistos que reducen los márgenes de ganancia. Una renderización, un análisis y una iteración más rápidos implican menos equipos creativos inactivos esperando la infraestructura.
En todos estos ejemplos, la limitación no reside en la cantidad de datos que se pueden almacenar. Es el momento de obtener información y tomar decisiones. Cuando la infraestructura proporciona respuestas con mayor rapidez, las organizaciones no solo ejecutan cargas de trabajo con mayor rapidez, sino que también obtienen resultados con mayor rapidez. Están reduciendo ciclos de decisión completos y extrayendo más valor de su recurso más preciado e irremplazable: el tiempo humano experto.
Imagine lo que su empresa podría lograr cuando el rendimiento aumenta y disminuye, deja de pagar por espacio libre y comienza a pagar por resultados.
Seguramente el titular debe ser: Deje de esperar por la infraestructura. CNQ entrega resultados más rápido. Pero ¿esto realmente lo abarca todo?
El efecto cumulativo
Al ofrecer 1.6 TB/s de rendimiento de lectura secuencial agregado sostenido, Qumulo superó el objetivo de rendimiento original del cliente en más del 50 % en comparación con los sistemas locales. Lograr este nivel de rendimiento requirió una arquitectura nativa de la nube, construida íntegramente sobre la infraestructura estándar de AWS y que abarca tres zonas de disponibilidad.
Más importante aún, este trabajo demuestra que el rendimiento extremo no requiere concesiones inasequibles.
Además del rendimiento de 1.6 TB/s, el sistema logró 20.7 millones de IOPS con una latencia de submilisegundos.
Pero el verdadero valor va más allá de las cifras. La arquitectura permite a los clientes aplicar la computación en todas las zonas de disponibilidad, en lugar de limitarse a una sola, lo que facilita considerablemente la adquisición de GPU y CPU a gran escala. Además, valida la resiliencia de CNQ en AWS, ofreciendo una disponibilidad de datos excepcional y una durabilidad excepcional, sin inflar los costos de almacenamiento por duplicación. Los clientes conservan la flexibilidad de elegir familias de instancias que se ajusten a sus necesidades de rendimiento y presupuesto, pagando solo por lo que realmente usan.
En conjunto, estas capacidades crean un efecto acumulativo, lo que llamamos Efecto cumulativo.
Quizás no sea solo un titular el que deba captar tu atención. Quizás sean todos.
- Qumulo nativo de la nube escalado a 1.6 TB/s en AWS
- CNQ diseñado para la nube, no adaptado a ella
- La arquitectura CNQ ofrece resiliencia multi-AZ sin duplicación de datos
- CNQ y el arte de hacer que la búsqueda de GPU sea soportable
- CNQ ofrece un rendimiento máximo sin compromisos de alto nivel
- Deje de esperar por la infraestructura. CNQ entrega resultados más rápido.
Esa combinación es la historia.
La comida para llevar
Esta implementación demostró que un sistema de archivos nativo de la nube puede ofrecer un rendimiento extremo sin sacrificar nada:
- Multi-AZ por diseño, no por duplicación
- Rendimiento que aumenta y disminuye
- Libertad para funcionar donde hay capacidad de procesamiento disponible, no donde están almacenados los datos
- Lo que resulta en tiempos de obtención de resultados más rápidos
La nube no solo tiene que ser lo suficientemente rápida. Con la arquitectura adecuada, puede ser más flexible, resiliente y económica que los sistemas locales.

