Présentation technique
Découvrez comment l'architecture cloud native unique de Qumulo fournit des services de données non structurés pour toutes vos charges de travail, qu'elles soient sur site, en périphérie ou dans le cloud public.
Table des Matières
Table des Matières
Courir n'importe où
Services de données et gestion du stockage
- La gestion du système
- Interface utilisateur Web
- Interface de ligne de commande
- API REST
- Nexus Qumulo
- Gestion des accès
- Fonctionnalités de sécurité des données
- Le tiering Active Directory
- Cryptage par fil
- Fonctionnalités de sécurité des données
- Authentification et contrôle d'accès
- Sécurité administrative
- Utilisateurs administrateurs au niveau du domaine
- Utilisateurs administrateurs locaux
- Authentification unique avec authentification multifacteur
- Jetons d'accès
- Contrôle d'accès basé sur les rôles
- Sécurité administrative
- Gestion de l'accès aux données
- Listes de contrôle d'accès
- Améliorations de Kerberos
- Prise en charge des autorisations multiprotocoles
- Autorisations d'accès aux objets
- Gestion des restrictions de circulation
- Listes de contrôle d'accès
Services de données
- Instantanés
- Verrouillage des instantanés
- Quotas
- Journalisation et audit des accès
- Détection d'intrusion
- Analyse du système et des données
- réplication
- Réplication continue
- Réplication basée sur un instantané
Le système de fichiers Qumulo
- Opérations sur le système de fichiers
- Évolutivité du système de fichiers
- Agrégation de métadonnées
- Espace de noms global Qumulo
Le magasin de blocs évolutif
- Système de transactions mondial
- Mise en cache et prélecture intelligentes
- Déploiements physiques
- Blocs virtuels protégés
- Chiffrement logiciel au repos
- Déploiements basés sur le cloud
Matériel serveur
Téléchargez cette ressource
Exécutez n'importe où, évoluez partout
Cloud Data Fabric de Qumulo vous permet d'étendre ou d'intégrer facilement vos applications dans n'importe quel environnement, n'importe où et sur n'importe quelle plateforme. Elle offre la seule solution de données non structurées unifiée à l'échelle mondiale et indépendante de la plateforme, compatible avec tous vos workflows d'entreprise, cloud hybride et multicloud. Le système de fichiers évolutif et les puissants outils d'interface Web et d'interface en ligne de commande de Qumulo simplifient la gestion des données, que ce soit pour vos workflows les plus exigeants ou pour un stockage d'archives cloud économique. Notre architecture cloud-native unique vous libère des contraintes de plateforme et de localisation, vous permettant d'accéder aux données où que vous soyez, que ce soit dans votre datacenter ou dans le cloud.
Chez Qumulo, notre objectif est de rendre le stockage de données non structurées simple, évolutif et global pour l'entreprise moderne. Nous simplifions la sécurisation de vos données. Nous simplifions l'exécution de vos flux de travail les plus exigeants, que ce soit sur site ou dans le cloud. Nous simplifions le stockage dans le cloud hybride.
Architecture logicielle de Qumulo
Nous avons conçu notre plateforme de stockage pour en faire un service évolutif et prêt pour le cloud, capable de prendre en charge n'importe quel flux de travail basé sur des fichiers, où que ce soit. Nous avons créé une plateforme extensible à l'échelle mondiale. Nous fournissons également des API robustes pour offrir une gestion automatisée et une visibilité en temps réel sur l'utilisation du système et des données. Nos solutions de stockage répondent aux exigences de sécurité et de protection des données des entreprises du Fortune 500.
Cette page fournit un aperçu de l'architecture, des composants et des services de la solution de données non structurées de Qumulo. Elle montre comment notre produit prend en charge un large éventail de cas d'utilisation, des médias et du divertissement aux soins de santé et aux sciences de la vie, du calcul haute performance basé sur le cloud au stockage d'archives cloud à long terme rentable. Nous montrerons également comment notre Cloud Data Fabric unique peut unifier les données critiques sur les plates-formes, les sites et les clouds pour offrir un accès en temps réel aux données distantes, rationaliser la collaboration entre des équipes très dispersées et accélérer le développement commercial dans pratiquement tous les secteurs.
Architecture de Qumulo
L'architecture modulaire de Qumulo peut être décomposée en une série de couches, avec des contrôles de service et des fonctionnalités spécifiques regroupés dans chaque couche. Ces couches fonctionnent ensemble pour prendre en charge l'évolutivité, les performances, la sécurité et la fiabilité des données non structurées sur une instance Qumulo, ainsi que du système Qumulo lui-même.
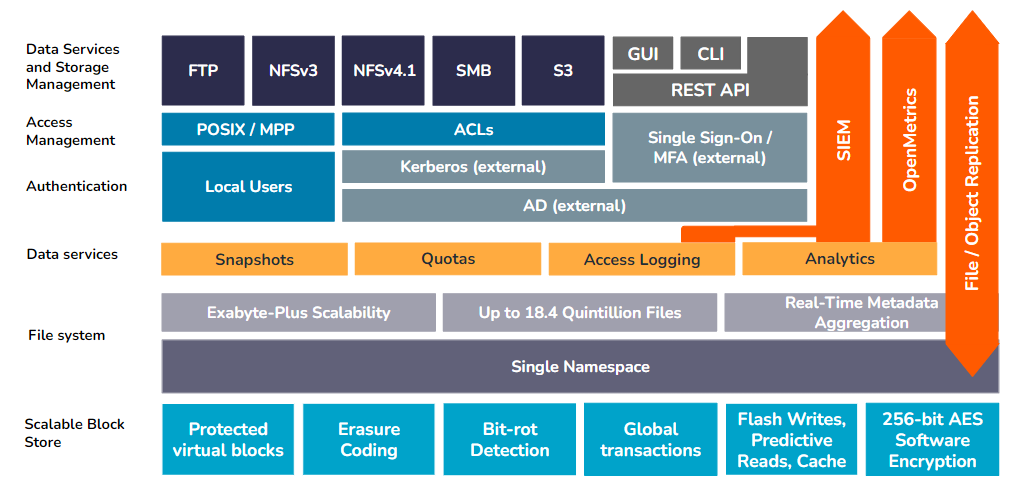
Principes fondamentaux de Qumulo
Avant de plonger dans les composants individuels de l'architecture de Qumulo, il existe plusieurs principes fondamentaux qu'il est important d'énumérer :
- Qumulo fournit un système de fichiers distribué 100 % défini par logiciel qui présente un espace de noms unique. Un cluster Qumulo sur site se compose d'une agrégation de nœuds indépendants sans partage, chaque nœud contribuant à la capacité et aux performances globales du cluster. Les nœuds individuels restent en coordination constante les uns avec les autres. Tout client peut se connecter à n'importe quel nœud et lire et écrire sur l'ensemble de l'espace de noms.
- Les instances Qumulo basées sur le cloud utilisent le stockage d'objets (AWS S3 ou le stockage Microsoft Azure Blob, selon l'endroit où elles sont déployées) pour la couche de données, dans laquelle les blocs associés à un fichier donné sont abstraits et distribués sur une collection logique d'objets discrets.
- Cette architecture cloud native élimine la relation héritée entre le calcul, le stockage et le débit, créant un service de stockage de fichiers entièrement élastique qui peut faire évoluer la capacité jusqu'à des centaines de pétaoctets et le débit au-delà de 100 Gbit/s.
- Grâce à la désagrégation complète des calculs et du stockage que permet l'architecture cloud native de Qumulo, les clients ont la possibilité de choisir les niveaux spécifiques de débit et de capacité dont ils ont besoin, indépendamment les uns des autres. Un client peut même déployer une instance Qumulo avec une empreinte de calcul initialement faible, puis faire évoluer temporairement l'allocation de calcul du service pour augmenter considérablement le débit pendant une brève période, puis le réduire à nouveau par la suite sans avoir à déployer de capacité supplémentaire à aucun moment.
- Qumulo est conçu pour évoluer. Nous garantissons que tous les aspects de notre produit peuvent prendre en charge sans problème des pétaoctets à des exaoctets de données, des milliards de fichiers, des millions d'opérations et des milliers d'utilisateurs sur des dizaines de sites, de régions et de déploiements.
- Qumulo est conçu pour la distribution géographique, permettant à des équipes largement dispersées de collaborer sur des ensembles de données partagés sans risque de corruption ou de perte de données.
- Qumulo s'auto-optimise pour des performances maximales. Chaque instance Qumulo suit l'accès aux données à l'aide d'une carte thermique pour identifier les blocs de données fréquemment consultés. Ces blocs sont déplacés de manière proactive par un algorithme de prélecture interne : les blocs de données sur les supports de stockage à long terme sont déplacés vers le stockage flash à mesure que leur score thermique augmente. Si le score thermique continue d'augmenter, les données qui se trouvent déjà sur le stockage flash sont déplacées de manière proactive vers la mémoire système pour un accès encore plus rapide. Au niveau mondial, sur toutes les instances Qumulo pour tous les clients Qumulo, le taux de réussite du cache est d'environ 95 % de toutes les demandes de lecture.
- Qumulo est hautement disponible et strictement cohérent, conçu pour résister aux pannes de composants dans l'infrastructure tout en fournissant un service fiable aux clients. Nous y parvenons grâce à l'utilisation de l'abstraction logicielle, du codage d'effacement, des technologies de réseau avancées et des tests rigoureux. Lorsque des données sont écrites dans le système de fichiers de Qumulo, l'opération d'écriture n'est pas confirmée au service, à l'utilisateur ou au client tant que les données n'ont pas été écrites dans le stockage persistant. Ainsi, toute demande de lecture ultérieure donnera lieu à une vue cohérente des données (par opposition à des modèles finalement cohérents).
- Qumulo fournit des services de fichiers indépendants de la plate-forme pour le cloud public, privé et hybride. Le logiciel de Qumulo fait peu d'hypothèses sur la plateforme sur laquelle il fonctionne. Il extrait les ressources matérielles physiques ou virtuelles sous-jacentes afin de profiter de la meilleure infrastructure de cloud public et privé. Cela nous permet de tirer parti de l’innovation rapide dans les technologies de calcul, de réseau et de stockage pilotée par les fournisseurs de cloud et l’écosystème des fabricants de composants.
- Le modèle de gestion Qumulo est axé sur l'API. Chaque fonctionnalité construite par Qumulo est d'abord développée en tant que point de terminaison d'API. Nous présentons ensuite un ensemble organisé de ces points de terminaison dans notre interface de ligne de commande (CLI) et WebUI, notre interface visuelle. Cela inclut la création de systèmes, la gestion des données, l’analyse des performances et des capacités, l’authentification et l’accessibilité des données.
- Qumulo expédie de nouveaux logiciels rapidement et régulièrement. Nous publions de nouvelles versions de nos logiciels toutes les quelques semaines. Cela nous permet de répondre rapidement aux commentaires des clients, de conduire une amélioration constante de notre produit et d'insister sur un code de qualité production de la part de nos équipes.
- L'architecture basée sur des conteneurs de Qumulo permet un processus de mise à niveau unique qui minimise les perturbations pour les utilisateurs et les flux de travail. De manière continue, nœud par nœud, le nouveau logiciel d'exploitation est déployé dans un conteneur parallèle à l'ancienne version. Une fois la nouvelle instance initialisée, l'ancien environnement est arrêté en douceur et la mise à niveau se poursuit vers le nœud suivant jusqu'à ce que l'ensemble du cluster soit mis à niveau.
- L'équipe Customer Success de Qumulo est très réactive, connectée et agile. Qumulo a la capacité de surveiller chaque déploiement Qumulo à distance via notre service Mission Qontrol basé sur le cloud, qui nous permet de suivre passivement la télémétrie de stockage et de service (nous n'avons pas la possibilité d'afficher ou d'accéder aux données du système de fichiers sur les déploiements des clients Qumulo). Notre équipe Customer Success utilise ces données pour aider les clients en cas d'incident, pour fournir un aperçu de l'utilisation des produits et pour alerter les clients lorsque leurs systèmes connaissent des pannes de composants. Cette combinaison de support intelligent et d'innovation rapide des produits permet d'obtenir un score NPS de 80+, le meilleur du secteur.
Le système de fichiers Qumulo
Toutes les données non structurées stockées sur un système de fichiers Qumulo sont organisées dans un espace de noms unique. Cet espace de noms est compatible POSIX pour prendre en charge les clients NFS3, tout en prenant également en charge la norme Access Control List utilisée par les protocoles NFSv4.1 et SMB.
Qumulo se distingue par plusieurs caractéristiques clés : sa capacité à faire évoluer un espace de noms unique vers pratiquement n'importe quelle taille, l'intégration transparente des analyses système et de données dans les opérations du système de fichiers, la prise en charge de S3 et des protocoles traditionnels comme NFS et SMB, et son approche innovante de la gestion des autorisations multiprotocoles.
Opérations sur le système de fichiers
Le système de fichiers de Qumulo a été conçu dès le départ pour évoluer de manière transparente vers une capacité de plus de l'exaoctet dans un espace de noms unique pouvant héberger des milliards de fichiers pouvant être partagés via les protocoles NFS et SMB standard. De plus, le système de fichiers a été conçu avec la capacité de surveiller efficacement les mises à jour et les actions du système de fichiers, et d'agréger les statistiques et les opérations basées sur les métadonnées, permettant ainsi des analyses système et des données en temps réel sans recourir à des parcours d'arborescence gourmands en ressources et en temps.
Évolutivité du système de fichiers
Une seule instance Qumulo peut évoluer jusqu'à des exaoctets de capacité et 264 nœuds (~18.4 quintillions de fichiers) sans aucun des problèmes communs aux autres plates-formes, tels que l'épuisement des inodes, les ralentissements des performances et les longs temps de récupération après des pannes de composants.
Agrégation de métadonnées
L'architecture unique de Qumulo suit les métadonnées en temps réel à mesure que les fichiers et les répertoires sont créés ou modifiés. Différents champs de métadonnées sont résumés pour créer un index virtuel. Au fur et à mesure des modifications, de nouvelles métadonnées agrégées sont collectées et propagées des fichiers individuels à la racine du système de fichiers. Chaque opération sur les fichiers et les répertoires est prise en compte et les modifications qui en résultent sont immédiatement intégrées dans les analyses du système. Les résultats, agrégés sur l'ensemble du système de fichiers, sont rendus visibles via le moteur d'analyse intégré de Qumulo, offrant une visibilité des données exploitables sans nécessiter de parcours coûteux de l'arborescence de la plateforme de données de fichiers.
Le magasin de blocs évolutif
Sous le système de fichiers Qumulo se trouve une couche modulaire protégée qui sert d'interface entre des milliards (ou plus) de fichiers et de répertoires et le support de données physique sur lequel ils sont stockés. Dans l'architecture modulaire de Qumulo, la couche Scalable Block Store remplit ce rôle.
Système de transactions mondial
Étant donné que Qumulo utilise une architecture distribuée et sans partage qui garantit une cohérence immédiate, chaque nœud du service doit disposer à tout moment d'une vue globale cohérente de toutes les données. Le magasin de blocs évolutif s'appuie sur une approche transactionnelle globale pour garantir que lorsqu'une opération d'écriture implique plusieurs blocs, l'opération écrira tous les blocs concernés ou aucun d'entre eux. Pour des performances optimales, le système maximise le parallélisme et le calcul distribué tout en préservant la cohérence transactionnelle des opérations d'E/S.
Cette approche minimise la quantité de verrouillage requise pour les opérations d’E/S transactionnelles et permet à tout déploiement Qumulo de s’adapter à plusieurs centaines de nœuds.
NeuralCache et prélecture intelligente
Le logiciel de Qumulo intègre un certain nombre de fonctionnalités inhérentes et de contrôles configurables, tous conçus pour protéger les données du cluster.
- Toutes les métadonnées, qui sont les plus souvent lues dans n'importe quel ensemble de données, résident en permanence sur le niveau Flash de l'instance de stockage.
- Les blocs virtuels fréquemment lus (mesurés par un « indice de chaleur » propriétaire) sont stockés sur mémoire flash, tandis que les blocs virtuels qui sont lus rarement sont déplacés vers un support plus froid, c'est-à-dire le niveau de disque dur du système (si disponible).
- Au fur et à mesure que les données sont lues, l'instance Qumulo surveille le comportement du client et pré-extrait intelligemment les nouvelles données dans la mémoire système sur le nœud le plus proche du client afin d'accélérer les temps d'accès.
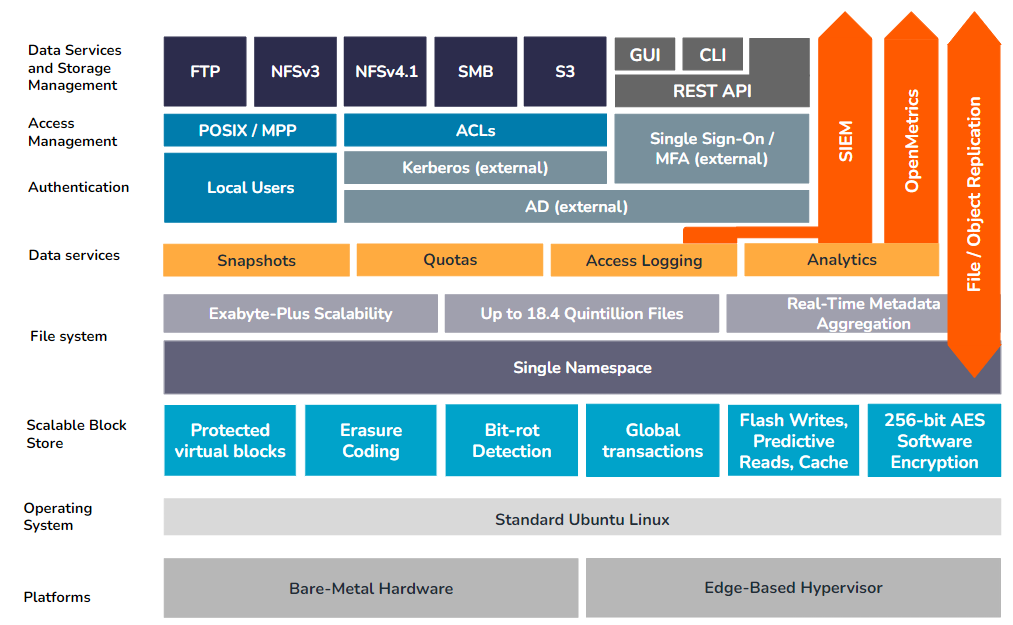
Déploiements physiques de Qumulo (clusters)
Sur un cluster Qumulo physique, le Scalable Block Store sert d'interface entre le système de fichiers et le support de stockage sous-jacent, qui peut être soit des périphériques flash SSD (Solid State Flash Devices) soit des disques durs HDD (HDD). Cette couche est principalement chargée de garantir la cohérence des données sur tous les nœuds d'un cluster physique, d'assurer des performances optimales pour les demandes de lecture et d'écriture, et de fournir la sécurité, l'intégrité et la résilience des données contre les pannes de composants.
Blocs virtuels protégés
La capacité de stockage d'un cluster physique Qumulo est organisée conceptuellement dans un espace d'adressage virtuel protégé. Chaque adresse de cet espace stocke soit un bloc de données de 4 Ko, soit un hachage de codage d'effacement de 4 Ko qui peut être utilisé pour reconstruire tous les blocs de données perdus en raison d'une défaillance matérielle. Le rapport entre les blocs de données et les blocs de codage d'effacement est déterminé par la taille du cluster physique. À mesure que des nœuds sont ajoutés, le rapport s'ajuste pour offrir une plus grande efficacité globale tout en protégeant contre les pannes de disque et de nœud.
En plus de la protection offerte par le codage d'effacement, le système de blocs virtuels comprend également un algorithme de détection de bit-rot pour protéger contre la corruption des données sur le disque.
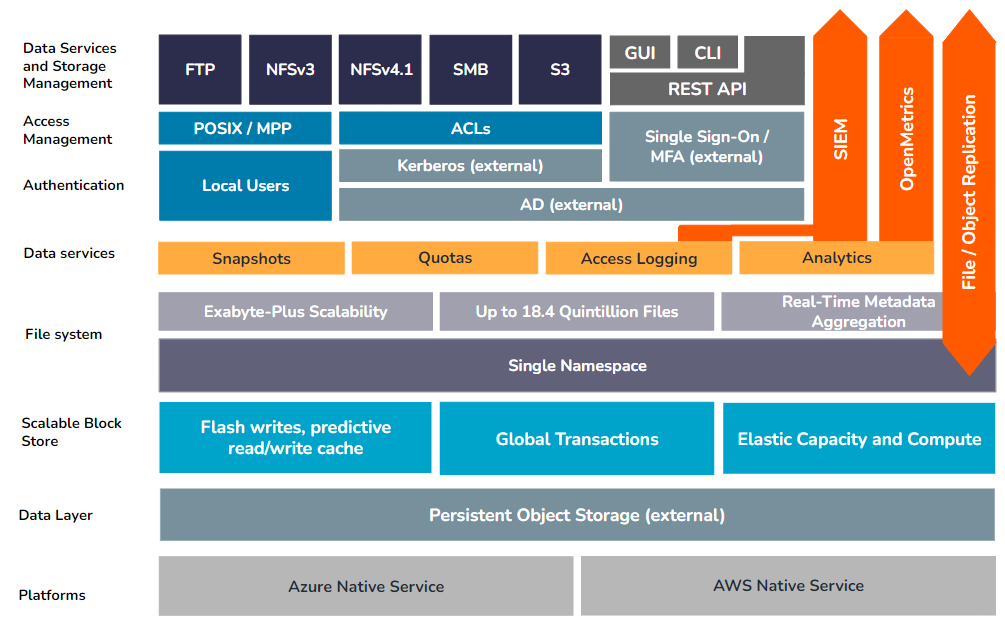
Instances Qumulo basées sur le cloud
Pour les instances Qumulo déployées sur Azure, de nombreuses fonctions fournies sur site par la couche Scalable Block Storage, telles que le chiffrement sur disque, le codage d'effacement, la détection de la pourriture des bits et la gestion des blocs, sont fournies en tant que fonctionnalités principales d'Azure sous-jacent. Service de stockage Blob.
Chiffrement au repos
Sur les clusters physiques Qumulo, le Scalable Block Store comprend un algorithme logiciel AES 256 bits qui crypte toutes les données du système de fichiers avant de les écrire dans la couche de données. Cet algorithme s'initialise dans le cadre du processus de création initial du cluster et regroupe toutes les données et métadonnées du système de fichiers au niveau du bloc pendant toute la durée de vie du cluster.
Les clusters Qumulo dans le cloud s'appuient sur un chiffrement au niveau des blocs sur la couche de stockage d'objets sous-jacente, implémenté et maintenu par le fournisseur de services cloud. Cela garantit que toutes les données au repos sur n'importe quelle instance Qumulo basée sur le cloud sont entièrement chiffrées.
Pour les entreprises qui en ont besoin, l’algorithme de chiffrement Qumulo intégré utilisé dans chaque cluster physique est conforme aux normes FIPS 140-2, tout comme les services de chiffrement fournis par le stockage d’objets Azure et AWS.
Services de données
La couche Data Services comprend cinq fonctionnalités de gestion : instantanés, réplication, quotas, journalisation et audit des accès, ainsi que analyses du système et des données.
Instantanés
Les instantanés sur un cluster Qumulo peuvent être utilisés de plusieurs manières pour protéger les données du cluster :
- Ils peuvent être utilisés localement pour une protection et une récupération des données rapides et efficaces.
- Un instantané des données en direct sur un cluster Qumulo peut être répliqué sur une instance Qumulo secondaire, telle qu'une instance de service Azure Native Qumulo Cold, qui pourrait prendre en charge un basculement immédiat des services de données de fichiers en cas de panne systémique à l'emplacement principal. .
- Les instantanés Qumulo peuvent également être associés à un logiciel de sauvegarde tiers pour fournir une protection efficace à long terme (avec un contrôle de version plus robuste pour les fichiers modifiés) contre la perte de données.
Verrouillage des instantanés
Pour fournir une protection supplémentaire contre les attaques de ransomwares ou la suppression prématurée d'instantanés critiques via un compte administrateur compromis, les instantanés peuvent être « verrouillés » cryptographiquement, empêchant ainsi la modification ou la suppression prématurée d'un instantané, même par un utilisateur administratif.
L'utilisation d'instantanés verrouillés nécessite une paire de clés cryptographiques asymétriques, avec la clé publique installée directement sur l'instance Qumulo et la clé privée stockée en externe conformément aux pratiques de gestion des clés établies par l'organisation.
Quotas
Les quotas permettent aux utilisateurs de contrôler la croissance de n'importe quel sous-ensemble d'un espace de noms Qumulo. Les quotas agissent comme des limites indépendantes sur la taille de n'importe quel répertoire, empêchant la croissance des données lorsque la limite de capacité est atteinte. Contrairement à d'autres plates-formes et services, les quotas Qumulo prennent effet instantanément, permettant aux administrateurs d'identifier les charges de travail malveillantes via nos analyses de capacité en temps réel et d'arrêter instantanément l'utilisation incontrôlée de la capacité. Les quotas suivent même la partie de l'espace de noms qu'ils couvrent lorsque les répertoires sont déplacés ou renommés.
Journalisation et audit des accès
La journalisation d'audit fournit un mécanisme de suivi des événements du système de fichiers Qumulo et des opérations de gestion. Lorsque les clients connectés émettent des requêtes vers le cluster, les messages du journal des événements décrivent chaque opération tentée. Ces messages de journal sont ensuite envoyés sur le réseau à une instance Syslog distante désignée, par exemple une plate-forme SIEM (Security Information and Event Management) standard du secteur telle que Splunk.
Détection des intrusions et des ransomwares en temps réel
Qumulo s'est associé aux fournisseurs tiers Superna et Varonis pour permettre la surveillance en temps réel des journaux d'événements et d'accès afin d'identifier et de répondre aux cyberattaques. Pour en savoir plus sur Varonis avec notre solution Azure Native Qumulo, visitez notre Intégration de Varonis avec ANQ page. Des informations sur Superna Ransomware Defender sont disponibles ici.
réplication
Le service de réplication intégré de Qumulo peut copier des données à grande échelle entre deux instances de stockage Qumulo. En plus de protéger les données contre les cyberattaques, un emplacement secondaire avec un autre cluster Qumulo peut également servir de stockage de secours en cas de panne au niveau du site.
Étant donné que toutes les instances Qumulo prennent en charge les mêmes fonctionnalités de réplication et fournissent les mêmes services quel que soit l'emplacement, la réplication peut être configurée pour s'exécuter dans n'importe quelle direction entre deux points de terminaison Qumulo, que ce soit sur site, dans AWS ou sur Azure.
Réplication continue
Cette forme de réplication consiste simplement à prendre un instantané des données du cluster Qumulo source et à le copier dans un répertoire d'un cluster cible. Tant que la relation de réplication est active, le système analyse tous les fichiers modifiés pour identifier et copier uniquement les modifications spécifiques apportées à la cible, en écrasant toutes les versions précédentes des données.
Réplication basée sur un instantané
Avec la réplication basée sur des instantanés, des instantanés sont également pris du répertoire cible sur le cluster secondaire. Une fois la tâche de réplication terminée, un nouvel instantané du répertoire cible est créé, ce qui garantit la cohérence des données entre les deux clusters, tout en conservant un journal des modifications et un historique des versions pour chaque fichier sur la cible.
Analyse du système et des données
La pile logicielle de Qumulo est conçue pour offrir un aperçu en temps réel des métriques du système et des services, y compris la capacité et les performances, dans chaque instance Qumulo. Cela permet aux clients de dépanner les applications, de gérer la consommation de capacité et de planifier des stratégies d'expansion (ou d'archivage). Les analyses de Qumulo sont alimentées par l'agrégation des modifications de métadonnées dans le système de fichiers au fur et à mesure qu'elles se produisent.
L'interface Web comprend des outils de surveillance en temps réel pour suivre les performances du système, l'utilisation de la capacité et l'activité actuelle sur l'instance Qumulo locale. Pour les entreprises qui souhaitent exporter ces informations vers une solution de surveillance externe, Qumulo prend en charge la norme API OpenMetrics pour l'exportation et la compilation des données Syslog.
Gestion des instances et des services de données
En tant que service de stockage de données de fichiers standard du secteur, Qumulo prend en charge tous les protocoles d'accès aux données non structurées : SMB, NFS et NFSv4.1. Il prend également en charge l'accès aux objets à l'aide de la norme de protocole S3. Qumulo prend également en charge l'accès FTP et API REST pour sélectionner les types de données.
La gestion du système
Toute instance Qumulo, qu'elle soit sur site ou dans le cloud, peut être gérée à l'aide des mêmes outils standard : une interface utilisateur Web intégrée pour le stockage interactif et la gestion des données, une bibliothèque de commandes basée sur la CLI ou un ensemble d'outils basés sur une API. outils de gestion.
Interface utilisateur Web
Qumulo propose une interface de gestion basée sur un navigateur, accessible depuis l'instance de stockage elle-même sans nécessiter de machine virtuelle ou de service distinct. L'interface utilisateur Web intuitive est organisée autour de six sections de navigation de niveau supérieur : Tableau de bord, Analyses, Partage, Cluster, API et outils et Support.
Interface de ligne de commande (CLI)
La CLI Qumulo prend en charge la plupart (mais pas la totalité) de la bibliothèque API et est axée sur l'administration système. La CLI offre une méthode d'interaction scriptable pour travailler avec une instance Qumulo. Une liste complète des commandes est disponible dans notre base de connaissances (care.qumulo.com).
API REST
L'API REST est un surensemble de toutes les fonctionnalités de la plateforme de données Qumulo. Depuis l'API, les administrateurs peuvent :
- Créer un espace de noms
- Configurer tous les aspects d'un système (de la sécurité, comme les services d'identité et les rôles de gestion du système, à la gestion et à la protection des données, y compris les quotas, les politiques de snapshot et/ou la réplication des données)
- Collecter des informations sur l'instance cible de Qumulo (y compris l'utilisation de la capacité et les points chauds de performances)
- Accéder aux données (y compris les opérations de lecture et d'écriture)
- L'API est « auto-documentée », ce qui permet aux développeurs et aux administrateurs d'explorer facilement chaque point de terminaison (et de voir des exemples de résultats). Qumulo conserve une collection d'exemples d'utilisation de notre API sur GitHub (https://qumulo.github.io/).
Nexus Qumulo
Les clients de Qumulo adoptent de plus en plus des opérations d'entreprise multi-cloud et multi-sites. Ils doivent donc réduire la complexité de la surveillance de la disponibilité et des mesures de service de chaque instance Qumulo via des interfaces de gestion distinctes. Avec Qumulo Nexus, les clients peuvent consolider les opérations de surveillance de toutes leurs instances Qumulo, qu'elles soient sur site, en périphérie ou dans le cloud, sous un portail de gestion unique qui offre les mêmes analyses en temps réel et la même visibilité des données que l'interface Web locale.
Gestion de la sécurité et des accès
Le logiciel de Qumulo intègre plusieurs fonctionnalités inhérentes et des contrôles configurables, tous conçus pour protéger l'accès aux données du cluster.
Fonctionnalités de sécurité des données Qumulo
Chaque instance Qumulo, qu'elle soit sur site ou dans le cloud, exploite une paire de contrôles qui garantissent que toutes les données du système de fichiers sont protégées contre la corruption, la perte ou l'intrusion au niveau du stockage des données.
Intégration Active Directory
Le modèle d'accès sécurisé de Qumulo a été conçu pour exploiter Microsoft Active Directory (AD) pour les droits et autorisations d'administrateur et d'utilisateur. Outre les avantages évidents d'une source unique d'enregistrement pour tous les comptes d'utilisateur, l'utilisation d'AD pour la gestion des privilèges et des autorisations prend en charge les meilleures pratiques du secteur pour les éléments suivants :
- Intégration transparente avec les protocoles d'authentification et de gestion des identités basés sur Kerberos
- Intégration avec les fournisseurs d'accès SSO et MFA
- Utilisation des autorisations basées sur la liste de contrôle d'accès pour les clients SMB et NFSv4.1 pour les données du système de fichiers
Cryptage des données par fil
Même avec des paramètres de sécurité de partage et de données appropriés en place, certaines entreprises ont besoin d'une couche supplémentaire de sécurité des données pour protéger les données contre tout accès non autorisé. Pour ces environnements, Qumulo prend également en charge le cryptage des données par fil vers et depuis les clients pris en charge.
Pour les partages SMB3, Qumulo prend en charge le chiffrement à l'échelle du cluster et par partage si nécessaire. Les exportations NFSv4.1 qui nécessitent une sécurité renforcée peuvent être configurées pour utiliser soit des signatures de paquets krb5i qui garantissent l'intégrité des données, soit un chiffrement de paquets basé sur krb5p pour empêcher l'interception pendant le transit.
Tout le trafic basé sur les objets est automatiquement chiffré à l'aide des normes de chiffrement TLS/HTTPS standard.
Authentification et contrôle d'accès
L'accès aux données du système de fichiers Qumulo, ainsi que l'accès au système de stockage Qumulo, utilisent des protocoles d'authentification et d'accès standard de l'industrie, garantissant une gestion des accès, un contrôle d'identité et une auditabilité de niveau entreprise.
Sécurité administrative
Les droits et privilèges au niveau du système sont accordés en fonction de l'appartenance à un ou plusieurs groupes locaux sur l'instance Qumulo individuelle. Les droits d'administration sont accordés à tous les comptes locaux et de domaine qui sont membres du groupe Administrateurs intégré du cluster.
Utilisateurs administratifs au niveau du domaine
La plupart des politiques de sécurité d'entreprise exigent que l'administration et la gestion des systèmes critiques de l'entreprise suivent une politique d'utilisateur unique et de compte unique afin de garantir des enregistrements précis de l'accès au système et de l'utilisation des privilèges. La méthode la plus simple pour se conformer à cette stratégie consiste à ajouter les comptes d'utilisateurs Active Directory concernés au groupe d'administrateurs local du cluster.
Utilisateurs administratifs locaux
Chaque instance Qumulo est livrée avec un compte par défaut, appelé admin, qui se voit automatiquement attribuer l'appartenance au groupe Administrateurs local et dispose de tous les droits et privilèges administratifs sur le cluster.
Authentification unique avec authentification multifacteur
L'authentification unique (SSO) élimine le besoin pour un administrateur de saisir à nouveau ses informations de connexion pour accéder au système. Les entreprises souhaitent le SSO non seulement parce qu'il rationalise le processus de connexion, ce qui facilite l'authentification des administrateurs, mais également parce qu'il réduit le risque de vol de compte via des enregistreurs de frappe ou d'interception lorsque la tentative de connexion traverse le réseau.
L'authentification multifacteur (MFA) ajoute une couche de sécurité supplémentaire au processus de connexion. Elle nécessite que les utilisateurs administrateurs récupèrent un code à usage unique à partir d'un jeton de clé ou d'une demande de vérification sur un appareil distinct, aucun des deux ne pouvant être en possession d'un intrus.
La solution SSO de Qumulo s'intègre à Active Directory via Security Assertion Markup Language (SAML) 2.0. Pour MFA, les clients peuvent tirer parti de n'importe quel fournisseur d'identité (IdP) qui s'intègre au domaine AD enregistré sur le cluster, notamment, mais sans s'y limiter, OneLogin, Okta, Duo et Azure AD.
Jetons d'accès
Pour simplifier le processus de stockage automatisé et de gestion des données via la fonctionnalité API de Qumulo, Qumulo offre aux administrateurs la possibilité de générer un jeton API à longue durée de vie qui peut être utilisé indéfiniment par des flux de travail automatisés jusqu'à ce que la clé soit révoquée ou supprimée. Le jeton est généré par un administrateur via CLI et peut être attaché à chaque flux de travail basé sur l'API, qui peut désormais effectuer des appels API authentifiés sans avoir à se connecter.
À des fins d'audit, chaque jeton est associé à un compte AD ou de cluster spécifique. Si le compte utilisateur associé est supprimé ou désactivé, le jeton d'accès cessera de fonctionner.
Contrôle d'accès basé sur les rôles
Le contrôle d'accès basé sur les rôles (RBAC) permet aux administrateurs d'attribuer des privilèges précis aux utilisateurs ou groupes non administratifs qui ont besoin de droits élevés sur le cluster pour des tâches de gestion spécifiques. L'utilisation du modèle RBAC permet la délégation sécurisée de privilèges selon les besoins sans avoir à conférer des droits d'administration complets. Il permet également aux entreprises d'accorder les privilèges système nécessaires tout en garantissant une piste d'audit vérifiable de l'accès et de l'utilisation des privilèges.
Gestion de l'accès aux données
Qumulo utilise le même modèle de sécurité pour gérer l'accès aux données du système de fichiers, en utilisant les pratiques, protocoles et outils standard de l'entreprise pour gérer et suivre l'accès à tous les fichiers et répertoires du système.
Listes de contrôle d'accès
Pour les charges de travail partagées via SMB et NFSv4, Qumulo prend en charge l'authentification via Active Directory et les listes de contrôle d'accès (ACL) de style Windows qui peuvent être partagées entre les deux protocoles.
Améliorations de Kerberos
Toutes les demandes de données SMB et NFSv4.1, si elles proviennent d'un client Windows ou Linux joint au même domaine que le cluster Qumulo (ou joint à un domaine approuvé), sont authentifiées à l'aide de la gestion de l'identité des utilisateurs basée sur Kerberos.
Prise en charge des autorisations multiprotocoles
Qumulo prend en charge la mise à disposition simultanée des mêmes données sur le système de fichiers sur plusieurs protocoles. Dans de nombreux cas, un partage SMB sur le cluster peut également être configuré en tant qu'exportation NFSv3, exportation NFSv4.1 et conteneur de stockage d'objets. Bien que cela maximise la flexibilité du cluster, certaines considérations doivent être prises en compte lorsqu'il s'agit de gérer les autorisations.
SMB et NFSv4.1 utilisent tous deux le même modèle d'autorisations basé sur ACL, dans lequel l'accès est accordé ou refusé à l'utilisateur en vertu de l'appartenance du compte Active Directory de l'utilisateur à un ou plusieurs groupes dont l'accès a été configuré au niveau des données.
Cependant, pour les charges de travail mixtes SMB/NFSv3, il peut y avoir une incompatibilité entre les autorisations ACL d'un fichier ou d'un répertoire donné et ses paramètres POSIX. Une instance Qumulo peut être configurée pour des opérations en mode mixte, dans lesquelles les autorisations SMB et POSIX sont conservées séparément pour les fichiers et les répertoires partagés entre les deux protocoles.
Pour les charges de travail à protocoles mixtes, le modèle propriétaire d'autorisations multiprotocoles (MPP) de Qumulo préserve les ACL SMB et l'héritage même si les autorisations NFS sont modifiées.
Autorisations d'accès aux objets
Si un répertoire du cluster est partagé via le protocole S3, il est traité comme un bucket S3 et tous les sous-répertoires et fichiers de ce répertoire sont traités comme des objets dans le bucket.
Lorsqu'un utilisateur ou un flux de travail tente d'accéder à un objet, le système utilise la clé d'accès fournie par le client pour identifier l'Active Directory ou l'ID utilisateur local mappé à la clé, puis vérifie cet ID par rapport à la liste de contrôle d'accès SMB/NFSv4.1 de l'objet.
Gestion des restrictions de circulation
En plus d'utiliser l'authentification basée sur SSO et MFA des comptes administratifs désignés, Qumulo prend également en charge les politiques de sécurité qui nécessitent la restriction de l'accès au niveau administrateur à des réseaux ou VLAN spécifiquement désignés en offrant la possibilité de bloquer des ports TCP spécifiques à un niveau VLAN individuel.
De cette manière, une instance Qumulo peut être configurée pour segmenter le trafic de gestion (par exemple, API, SSH, interface utilisateur Web et trafic de réplication) du trafic client (par exemple, SMB, NFS et accès aux objets).
Tissu de données en nuage
Dans un monde interconnecté et multi-cloud, les applications et les équipes géographiquement dispersées ont besoin de pouvoir collaborer sur des ensembles de données partagés sans la latence d'une connexion WAN ou la longue attente pour répliquer les données à grande échelle entre les sites.
Cloud Data Fabric (CDF) de Qumulo étend le système de fichiers évolutif de Qumulo sur deux ou plusieurs instances Qumulo, permettant aux équipes et aux flux de travail géographiquement dispersés de partager un ensemble de données unique en temps réel. CDF offre non seulement un accès à faible latence aux données critiques entre les instances Qumulo sur site, en périphérie et dans le cloud ; dans de nombreux cas, il élimine entièrement le besoin de réplication à grande échelle dans les flux de travail partagés.
CDF unifie un ou plusieurs ensembles de données partagés sur plusieurs sites, clouds, plateformes et zones géographiques, mettant ainsi les données à la disposition des équipes, des applications et des organisations qui doivent collaborer en temps réel. L'utilisation de CDF permet aux entreprises de minimiser le trafic WAN tout en simplifiant la gestion des données et de la sécurité entre les sites.
Espace de noms global
Cloud Data Fabric de Qumulo permet de créer un espace de noms véritablement mondial dans lequel les ensembles de données critiques sont partagés entre les instances Qumulo partout : dans le centre de données, dans le cloud et en périphérie. L'espace de noms mondial de Qumulo utilise des fonctionnalités innovantes uniques qui se combinent pour permettre une visibilité des données en temps réel et une collaboration mondiale sur les données partagées.
Synchronisation des métadonnées
Au lieu de synchroniser immédiatement les données des fichiers et des dossiers sur toutes les instances qui partagent un ensemble de données donné, l'implémentation de l'espace de noms global de Qumulo réplique initialement uniquement les métadonnées entre les points de terminaison Qumulo, permettant aux clients distants de voir l'intégralité de la structure des fichiers et des dossiers des ensembles de données distants avec seulement quelques millisecondes de retard.
Verrouillage distribué
Pour garantir l'intégrité des données dans un environnement distribué où n'importe quel fichier peut être modifié par n'importe quel utilisateur ou application sur plusieurs sites, CDF utilise un algorithme de verrouillage qui coordonne l'accès aux fichiers sur tous les points de terminaison. Cela garantit que chaque transaction de données est autorisée, enregistrée et strictement cohérente avec toutes les actions précédentes.
Sécurité des données
La réplication des métadonnées du système de fichiers entre les points de terminaison réplique également les ACL (SMB et NFSv4.1) et les autorisations POSIX. Si tous les utilisateurs du portail partagent la même source d'authentification, l'accès aux données est automatiquement transféré entre les points de terminaison.
Si un portail est supprimé, les liens vers tous les points de terminaison spoke sont interrompus et toutes les données mises en cache localement sont supprimées de chaque spoke. À moins que le partage ou l'exportation sous-jacent ne soit également supprimé, les données restent sur l'instance Qumulo qui a servi de point de terminaison hub.
Portails de données
L'approche unique de Cloud Data Fabric en matière d'accès unifié aux données repose sur des portails de données. Les portails sont publiés au niveau du partage SMB individuel ou de l'exportation NFS (ou des deux, car Qumulo propose également le partage de données multiprotocole). La création d'un portail CDF rend les données de ce partage ou de cette exportation disponibles pour une ou plusieurs instances Qumulo supplémentaires.
Les portails CDF peuvent prendre en charge les cas d'utilisation en lecture seule et bidirectionnels.
Points de terminaison du portail
Les portails Cloud Data Fabric sont conçus selon une topologie en étoile, dans laquelle une instance Qumulo (le « hub ») fait office de propriétaire officiel des données du portail et coordonne toutes les opérations d'accès aux données sur tous les points de terminaison du portail. Chaque portail dispose d'un hub unique, avec un ou plusieurs points de terminaison « spoke » agissant comme des extensions de l'espace de noms du portail.
Pour créer un nouveau portail, un administrateur identifie le partage ou l'exportation spécifique sur le hub à publier, attribue au moins un point de terminaison Qumulo supplémentaire en tant que spoke et désigne le nouveau portail comme étant en lecture seule ou bidirectionnel. Des instances Qumulo supplémentaires peuvent être ajoutées au portail en tant que spokes, le cas échéant.
Chaque point de terminaison d'un portail CDF peut également fonctionner comme une instance de stockage Qumulo indépendante, hébergeant des partages et/ou des exportations supplémentaires limités à l'utilisation par les clients locaux uniquement.
Journalisation journalisée
Toutes les opérations du système de fichiers au sein d'un portail donné sont suivies via un mécanisme de journalisation distribué. Chaque événement d'accès aux données (création, lecture, modification, suppression, etc.) est enregistré dans le journal partagé et répliqué sur tous les autres points de terminaison du portail.
Suivi du temps logique
L'utilisation d'un décalage temporel logique partagé pour coordonner les événements entre les points de terminaison, plutôt qu'un horodatage physique absolu, garantit que les transactions de données sont appliquées dans le bon ordre sur tous les nœuds de tous les points de terminaison sans avoir à concilier les différences de fuseau horaire ou les décalages horaires entre les différentes instances de Qumulo.
Journalisation et récupération logiques
Si un spoke du portail perd sa connectivité avec le hub, les données du portail ne sont plus disponibles pour aucun des clients de ce spoke. Sur les autres points de terminaison du portail, le fichier journal distribué continue de suivre les modifications apportées aux données au sein du portail.
Lors de la reconnexion, le rayon affecté rejouera les événements du journal dans leur séquence appropriée pour réconcilier ses données mises en cache localement avec le reste des points de terminaison du portail.
Optimisation des transferts
Cloud Data Fabric a été conçu pour tirer le meilleur parti d'une bande passante limitée, en offrant un accès hautes performances et à faible latence aux données distantes à grande échelle, même dans les entreprises largement distribuées. Pour ce faire, il attend que les clients demandent les données de portail spécifiques dont ils ont besoin, met en cache uniquement les données pertinentes localement sur chaque point de terminaison et réplique uniquement les blocs de données modifiés entre les points de terminaison plutôt que des fichiers entiers ou des ensembles de données entiers.
Mise en cache locale
Le premier accès aux données à partir d'un point de terminaison distant entraîne l'extraction du fichier ou du dossier demandé sur le réseau et sa mise en cache sur le point de terminaison Qumulo local. En supposant qu'aucune modification ne soit apportée aux données après le premier accès, toutes les demandes d'accès ultérieures pour les mêmes données seront traitées à partir du cache local.
Systèmes de fichiers épars
Chaque rayon crée un système de fichiers fantôme, indépendant de toutes les autres données de fichiers qu'il héberge localement, contenant les métadonnées du portail ainsi que toutes les données de portail mises en cache localement. L'instance locale utilise une carte thermique, similaire mais indépendante du système de mise en cache intelligent qui optimise les performances de lecture du système de fichiers local, pour surveiller la fréquence à laquelle les données mises en cache sont consultées.
La taille de ce système de fichiers clairsemé varie en fonction de la capacité de stockage disponible de l'instance Qumulo spécifique. À mesure que de nouvelles données de portail sont demandées et que le système de fichiers clairsemé se remplit, les données plus anciennes sont vidées du cache pour garantir des performances optimales pour les nouvelles données entrantes.
Mise en cache prédictive
À mesure que les clients et applications locaux accèdent aux fichiers et aux dossiers, chaque point de terminaison surveille les données du portail ajoutées passivement au cache du système de fichiers clairsemé au fil du temps et commence à identifier les modèles de comportement des clients et des applications. CDF utilise ces modèles d'accès pour anticiper les blocs de données susceptibles d'être demandés ensuite et pré-récupère de manière préventive ces blocs dans le cache du système de fichiers clairsemé avant qu'ils ne soient demandés.
Matériel serveur
Le logiciel de Qumulo fonctionne sur pratiquement n'importe quel matériel standard de niveau professionnel basé sur x86-64, bien que les clients à la recherche d'une disponibilité et de performances optimales doivent consulter directement Qumulo avant de choisir la configuration matérielle appropriée.
Le système d'exploitation Linux sous-jacent est verrouillé, permettant uniquement les opérations nécessaires pour effectuer les tâches de support requises de l'environnement logiciel Qumulo. D'autres services Linux standard ont été désactivés afin de réduire davantage le risque d'attaque.
Pile logicielle entièrement native
Bien que Linux inclut des composants open source pour fournir à la fois des services client et serveur NFS et SMB (par exemple Samba, Ganesha, etc.), ces services ne sont pas inclus dans l'image Ubuntu renforcée qui prend en charge l'environnement logiciel Qumulo. Qumulo développe et contrôle tout le code utilisé pour les protocoles d'accès aux données NFS, SMB, FTP et S3 – dans l'environnement d'exploitation Qumulo.
Mises à jour instantanées
Le processus de développement itératif de Qumulo est simple et rationalisé, avec de nouvelles mises à jour logicielles publiées régulièrement. Cela permet une innovation rapide pour développer et déployer de nouvelles fonctionnalités et favorise une plateforme de stockage plus sécurisée.
Qumulo a conçu le processus de mise à niveau pour qu'il soit rapide et simple. La pile logicielle Qumulo Core est entièrement conteneurisée, ce qui permet la mise à niveau d'un cluster entier en 20 secondes, quelle que soit sa taille. Le besoin de restauration est éliminé puisque la fonctionnalité et la stabilité de la version mise à jour peuvent être entièrement validées avant l'arrêt de l'ancienne version.