Technische Übersicht
Qumulo Core ist eine leistungsstarke Dateidatenplattform. So funktioniert das.
Unsere Mission: Schöpfer und Innovatoren ermöglichen
Unser Ziel bei Qumulo ist es, das Komplexe radikal einfach zu machen. Wir möchten die Sicherung Ihrer Daten einfach machen. Wir möchten die Einführung neuer Plattformen einfach machen. Wir möchten die Bereitstellung anspruchsvoller Workflows (zu geringen Kosten) einfach machen. Wir wollen die Hybrid Cloud einfach machen.
Die Mission von Qumulo besteht darin, Innovatoren zu helfen, die Kraft ihrer Daten zu entfesseln, wo immer sie sich befinden. Innovatoren schaffen neue Geschäfte, Behandlungen, Produkte und Kunst, indem sie Daten in Werte verwandeln. Diese Transformation basiert auf einem Datenlebenszyklus, in dem Mitarbeiter ihre Daten erfassen, interagieren, transformieren, veröffentlichen und dann archivieren. Innerhalb dieses Lebenszyklus verwenden „Schöpfer“ (Künstler, Forscher usw.) digitale Daten, um ihre Arbeit zu erledigen. Wir sehen diesen Wandel in mehreren Branchen in Aktion.
Biowissenschaften
Wissenschaftler untersuchen Daten, die von Sequenzern erfasst wurden, um Anomalien zu identifizieren, und wandeln dann Rechencluster die Rohdaten in fertige Entdeckungen um. Diese Entdeckungen werden in der Forschungsgemeinschaft veröffentlicht, dann werden die Daten archiviert.
Medien und Unterhaltung
Künstler bearbeiten Daten, die bei täglichen Drehs aufgenommen wurden, um erste Szenen zu erstellen, und verwandeln diese dann in Renderpipelines in einen fertigen Film. Distributoren veröffentlichen diesen Film in Online-Verkaufsstellen, und der fertige Inhalt wird archiviert.
Fertigung & IoT
Protokolle und Bilder werden von Sensoren (mit hohem Volumen, Geschwindigkeit und Vielfalt) generiert und in Echtzeit auf Komponentenfehler analysiert. Später überprüfen Geschäftsanalysten die Daten, um Möglichkeiten für Prozessverbesserungen zu erkunden, und Datenwissenschaftler, um bessere Modelle für maschinelles Lernen zu erstellen. Diese Modelle werden in der Fertigungslinie veröffentlicht, um die Produktionseffizienz zu verbessern, und fertige Protokolle und Bilder werden archiviert.
Anforderungen an eine Dateidatenplattform
Um Innovationen voranzutreiben, sind Unternehmen auf unstrukturierte Dateidatenplattformen angewiesen. Diese Plattformen bieten dauerhaften Speicher für die Daten, die Innovationen vorantreiben. Sie bieten einen einfachen, schnellen und zuverlässigen Zugriff auf die Ersteller und Rechenfarmen, die Daten in Entdeckungen umwandeln. Innovatoren verlangen, dass ihre unstrukturierten Datenplattformen:
Seien Sie Cloud-fähig
Es müssen Plattformen für öffentliche, private und hybride Cloud-Infrastrukturen gebaut werden, die unstrukturierte Datendienste in der öffentlichen Cloud und im Rechenzentrum anbieten. Sie sollten sich auch nahtlos in das Ökosystem der Cloud-Dienste einfügen (z. B. Machine Learning (ML), Publishing oder Cloud-Objektspeicherdienste).
Skalieren
Plattformen müssen in der Lage sein, Petabyte an Daten, Milliarden von Dateien, Millionen von Operationen und Tausende von Benutzern bereitzustellen.
Mit Standardwerkzeugen arbeiten
Die wertvollsten Entwickler in einem innovativen Unternehmen (Künstler, Forscher, Datenwissenschaftler und Analysten) müssen in der Lage sein, ihre Tools zu verwenden, ohne benutzerdefinierte Treiber installieren oder ihren Workflow ändern zu müssen.
- Bieten Sie Transparenz und Automatisierung
Administratoren müssen in der Lage sein, Datendienste mithilfe von RESTful-APIs zu erstellen, zu verwalten und zu beenden. Sie müssen in der Lage sein, die Leistung und Kapazitätsauslastung ihrer Datendienste in Echtzeit zu verstehen, um Probleme besser diagnostizieren und für die Zukunft planen zu können.
- Sicher und unternehmenstauglich
Daten sind das Lebenselixier innovativer Unternehmen und müssen daher mit branchenüblichen Identitäts- und Verschlüsselungstools geschützt werden. Die Datenplattform muss die Unternehmensanforderungen an Disaster Recovery, Backup und Benutzerverwaltung erfüllen.
Die Herausforderungen mit bestehenden Lösungen
Organisationen, die von Daten profitieren, um Innovationen voranzutreiben, werden von verfügbaren unstrukturierten Datenplattformen schlecht bedient.
Open-Source- und Windows-basierte Dateidatenplattformen lassen sich schlecht skalieren, lassen sich nur schwer automatisch bereitstellen und erfordern einen erheblichen Verwaltungsaufwand.
Ältere Dateidatenplattformen, die auf Hardware-Appliances basieren, verfügen nicht über Echtzeit-Sichtbarkeitsfunktionen, bieten unvollständige API-Oberflächen und können öffentliche Cloud-Workloads nur über an die Cloud angrenzende Hardware-as-a-Service-Angebote unterstützen. Scale-Up-Varianten wie NetApp haben Schwierigkeiten, einzelne Namespaces über 100 TB hinaus zu skalieren.
Cloud-Objekt- und Dateidienste unterstützen viele Cloud-Innovations-Workloads, ermöglichen es den Entwicklern jedoch nicht, ihre Standardtools zu verwenden, was hauptsächlich auf die fehlende Unterstützung mehrerer Protokolldateien zurückzuführen ist. Darüber hinaus fehlen ihnen viele der Sicherheits- und Unternehmensfunktionen, die Unternehmen benötigen, um Arbeitslasten in die öffentliche Cloud zu verlagern.
Lokale Objektspeicher bieten kostengünstige Datenspeicherung, sind jedoch aufgrund schlechter Leistung und mangelnder Unterstützung für Standard-Endbenutzertools grundsätzlich nicht für die interaktiven und transformativen Phasen des Datenlebenszyklus geeignet.
Die Softwarearchitektur von Qumulo
Qumulo wurde gegründet, um Entwicklern eine unstrukturierte Datenplattform für private und öffentliche Clouds zu ermöglichen.
Wir verpacken diese Plattform in Cloud-fähige, skalierbare Produkte, die es Entwicklern ermöglichen, wichtige Tools zu verwenden. Wir bieten auch robuste APIs für die Verwaltung und Echtzeit-Sichtbarkeit der Systemnutzung und erfüllen die Sicherheits- und Datenschutzanforderungen von Fortune-500-Unternehmen.
Der Zweck dieses Dokuments besteht darin, einen Überblick über die Architektur der Dateidatenplattform von Qumulo zu geben, um zu veranschaulichen, wie unser Produkt Innovatoren und Entwicklern die oben genannten Vorteile bietet. Um die architektonische Differenzierung und den Wert unserer Plattform zu veranschaulichen, werden wir die wichtigsten Schichten unserer Software untersuchen. Auf jeder Ebene werden wir den Zweck der Ebene beschreiben, wie sie Elemente unseres Wertversprechens liefert und welche Innovation diesen Wert antreibt.
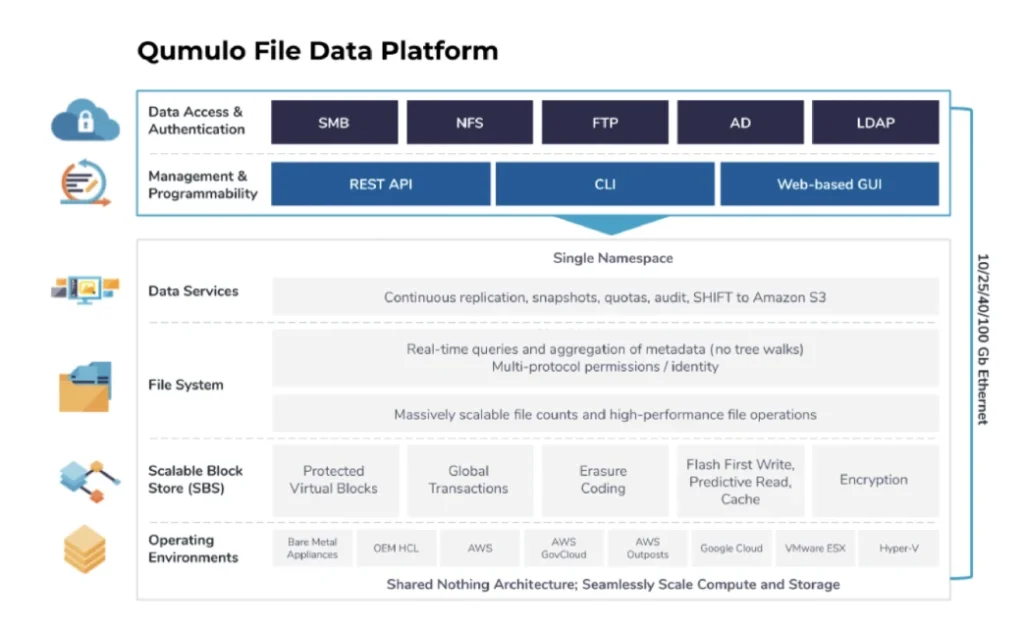
Grundlagen der Qumulo File Data Platform
Bevor Sie in die einzelnen Komponenten der Dateidatenplattform eintauchen, gibt es einige grundlegende Annahmen, die für das Verständnis der Qumulo-Architektur wichtig sind:
1. Qumulo stellt ein verteiltes System bereit, das einen einzigen Namespace darstellt. Die Dateidatenplattform von Qumulo besteht aus Shared-Nothing-Clustern unabhängiger Knoten. Jeder Knoten bietet Kapazität und Leistung. Einzelne Knoten stehen in ständiger Koordination miteinander. Jeder Client kann sich mit jedem Knoten verbinden und im Namespace lesen und schreiben.
2. Die Dateidatenplattform von Qumulo ist skalierbar. Wir stellen sicher, dass alle Aspekte unseres Produkts problemlos Petabytes an Daten, Milliarden von Dateien, Millionen von Vorgängen und Tausende von Benutzern unterstützen können.
3. Die Dateidatenplattform von Qumulo ist hochverfügbar und sofort konsistent. Die unstrukturierte Datenplattform von Qumulo ist so konzipiert, dass sie Komponentenausfällen in der Infrastruktur standhält und den Kunden dennoch einen zuverlässigen Service bietet. Dies erreichen wir durch den Einsatz von Software-Abstraktion, Erasure Coding, fortschrittlichen Netzwerktechnologien und strengen Tests. Wenn Daten in die Software von Qumulo geschrieben werden, erkennen wir diesen Schreibvorgang an den Dienst, den Benutzer oder den Rechenknoten erst dann an, wenn wir diese Daten im dauerhaften Speicher gespeichert haben. Daher erfolgt bei jedem Lesevorgang eine kohärente Sicht auf die Daten (im Gegensatz zu eventuell konsistenten Modellen).
4. Qumulo liefert Software, die für die öffentliche, private und hybride Cloud entwickelt wurde. Die Software von Qumulo macht kaum Annahmen über die Plattform, auf der sie läuft. Es abstrahiert die zugrunde liegenden physischen oder virtuellen Hardwareressourcen, um die beste öffentliche und private Cloud-Infrastruktur zu nutzen. Dies ermöglicht es uns, die schnellen Innovationen bei Rechen-, Netzwerk- und Speichertechnologien zu nutzen, die von den Cloud-Anbietern und dem Ökosystem der Komponentenhersteller vorangetrieben werden.
5. Die Qumulo-Dateidatenplattform ist API-first. Jede von Qumulo entwickelte Funktion entsteht zunächst als API-Endpunkt. Anschließend präsentieren wir einen kuratierten Satz dieser Endpunkte in unserer Befehlszeilenschnittstelle (CLI) und unserer visuellen Schnittstelle. Dazu gehören Systemerstellung, Datenverwaltung, Leistungs- und Kapazitätsanalyse, Authentifizierung und Datenzugänglichkeit.
6. Qumulo liefert schnell und regelmäßig neue Software. Wir veröffentlichen alle zwei Wochen neue Versionen unserer Software. Dies ermöglicht es uns, schnell auf Kundenfeedback zu reagieren, die kontinuierliche Verbesserung unseres Produkts voranzutreiben und von unseren Teams auf Code in Produktionsqualität zu bestehen.
7. Das Kundenerfolgsteam von Qumulo ist äußerst reaktionsschnell, vernetzt und agil. Jede Dateidatenplattform von Qumulo bietet die Möglichkeit, über unseren cloudbasierten Überwachungsdienst Mission Qontrol eine Verbindung zur Fernüberwachung herzustellen. Unser Kundenerfolgsteam nutzt diese Daten, um Kunden bei Vorfällen zu helfen, Einblicke in die Produktnutzung zu geben und Kunden zu warnen, wenn in ihren Systemen Komponentenausfälle auftreten. Diese Kombination aus intelligentem Support und schneller Produktinnovation führt zu einem branchenführenden NPS-Wert von 80+.
Datenzugriff und Authentifizierung
Zweck
Ermöglichen Sie den Zugriff auf Daten mithilfe von Standardanwendungen und Betriebssystemen und gewährleisten Sie gleichzeitig eine Identitätskontrolle auf Unternehmensniveau.
So funktioniert's
Unsere Datenzugriffsschicht unterstützt die drei von Entwicklern am häufigsten verwendeten Dateizugriffsprotokolle (NFS, SMB und FTP). Diese Protokolle sind als unabhängige und skalierbare Ressourcen auf jedem Knoten eines Qumulo-Clusters vorhanden. Endbenutzer sehen einen einzigen Namespace, der in Kapazität und Leistung erweitert werden kann. Auf diesen Namespace kann nahtlos von jedem Windows-, Mac- oder Linux-Computergerät und daher von jeder unstrukturierten Datenanwendung aus zugegriffen werden.
Unsere Authentifizierungsschicht unterstützt die beiden Industriestandard-Identitätsdienste: Active Directory (AD) und Lightweight Directory Access Protocol (LDAP). Die Datendienste von Qumulo lassen sich in diese von den Kunden verwalteten globalen Identitätssysteme integrieren, sodass der Zugriff über Computing, Endbenutzer und Daten gesteuert werden kann. Die Verbindung der Qumulo-Dateidatenplattform mit Identitätsdiensten erfordert eine einfache Einrichtung und funktioniert gut mit komplexen und verteilten Identitätsdienstkonfigurationen (eine häufige Herausforderung in privaten und öffentlichen Cloud-Umgebungen von Unternehmen).
Jedes Datenzugriffsprotokoll verwendet eine gemeinsame Authentifizierungsschicht, um mit den in unserer Dateidatenplattform gespeicherten Daten zu interagieren. Dadurch können Benutzer zwischen Anwendungen, Betriebssystemen und Umgebungen wechseln und gleichzeitig auf dieselben Daten zugreifen. Während sich die Daten durch den Datenlebenszyklus bewegen (von der Erfassung über die Transformation bis hin zur Archivierung), bietet diese Trennung der Schichten entscheidende Flexibilität und reduziert die Anzahl der Systeme, die Kunden warten müssen.
Innovationspunkte
Die Datenzugriffsprotokolle von Qumulo ermöglichen es Benutzern, jedes Standard-Windows-, Mac- oder Linux-Betriebssystem und jede Standardanwendung zu nutzen, ohne Änderungen an ihrer Umgebung vorzunehmen.
Qumulo unterstützt sowohl zustandsbehaftete (SMB) als auch zustandslose (NFS) Datenzugriffsprotokolle aus demselben skalierbaren Namespace.
Qumulo ermöglicht Identitätsmanagement der Enterprise-Klasse in einem skalierbaren System mit hoher Verfügbarkeit.
Verwaltung und Programmierbarkeit
Zweck
Ermöglichen Sie Anwendungsbesitzern, integrierte Lösungen mit der Qumulo-Dateidatenplattform zu erstellen, und ermöglichen Sie Administratoren, ihre Datendienste zu automatisieren und zu verwalten.
So funktioniert's
Die Management- und Programmierbarkeitsschicht besteht aus drei Funktionen; eine REST-API, eine Befehlszeilenschnittstelle (CLI) und eine visuelle Schnittstelle.
Die REST-API
Die REST-API ist eine Obermenge aller Funktionen der Qumulo-Datenplattform. Über die API können Kunden:
- Erstellen Sie einen Namespace (in der Cloud mithilfe einer Terraform- oder Cloud Formation-Vorlage)
- Konfigurieren Sie alle Aspekte eines Systems (von der Sicherheit wie Identitätsdienste oder Verwaltungsrollen über das Datenmanagement wie Kontingente bis zum Datenschutz wie Snapshot-Richtlinien oder Datenreplikation bis hin zum Hinzufügen neuer Kapazitäten)
- Sammeln von Informationen über ihr System (einschließlich Kapazitätsauslastung und Leistungs-Hotspots)
- Zugriffsdaten (einschließlich Lese- und Schreibvorgänge)
Die API ist „selbstdokumentierend“ und macht es Entwicklern und Administratoren leicht, jeden Endpunkt zu erkunden (und Beispielausgaben anzuzeigen). Qumulo unterhält eine Sammlung von Beispielverwendungen unserer API auf Github (https://qumulo.github.io/).
Die Befehlszeilenschnittstelle (CLI)
Die Qumulo-CLI bietet die meisten (aber nicht alle) der API und richtet sich an Systemadministratoren. Die CLI bietet eine skriptfähige Interaktionsmethode für die Arbeit mit einem Qumulo-System. Die CLI bietet ca. 200 eindeutige Befehle (ab Qumulo Core Version 3.0.3). Eine vollständige Liste der Befehle finden Sie in unserer Wissensdatenbank (www.care.qumulo.com).
Die visuelle Schnittstelle
Die visuelle Benutzeroberfläche von Qumulo bietet eine benutzerorientierte Möglichkeit zur Interaktion mit einer Qumulo-Dateidatenplattform. Die visuelle Schnittstelle ist eine webbasierte Schnittstelle, die vom System bedient wird, ohne dass eine separate VM oder ein separater Dienst erforderlich ist. Die visuelle Benutzeroberfläche ist um sechs Navigationsabschnitte auf oberster Ebene herum organisiert: Dashboard, Analytics, Sharing, Cluster, API & Tools und Support.
Dashboard
Dies ist die „Homepage“ der visuellen Benutzeroberfläche von Qumulo. Es bietet eine Reihe leicht verdaulicher Einblicke in die Aktivität, das Wachstum, die Leistung und den Zustand einer Qumulo-Dateidatenplattform. Das Dashboard visualisiert die verfügbare und genutzte Kapazität (einschließlich Daten, Metadaten und Snapshots), das Kapazitätswachstum und das Wachstum der Dateianzahl, die Gesamtleistung des Systems und das Gleichgewicht der Workloads.
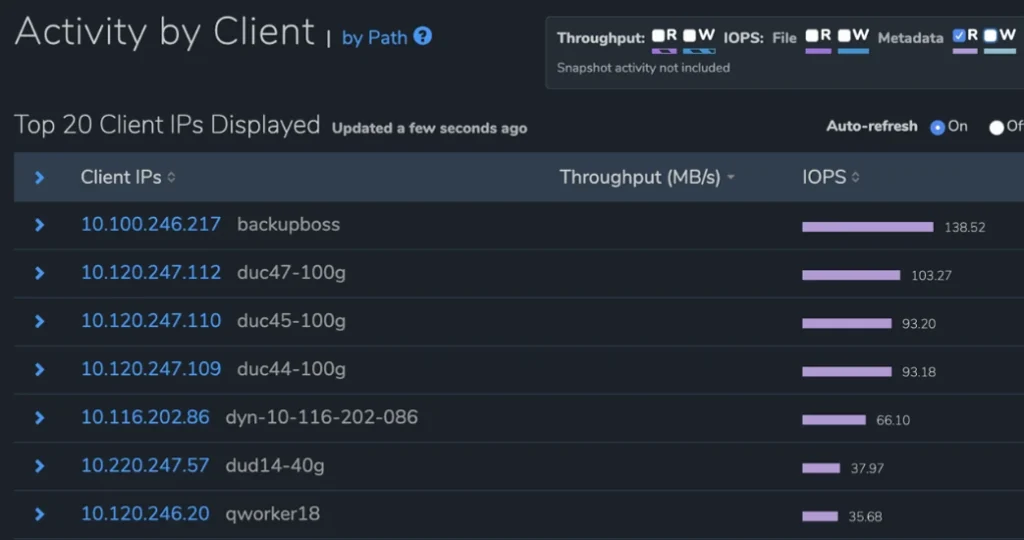
Analyse
Dieser Abschnitt bietet Systemadministratoren eine detaillierte Echtzeitansicht ihrer Systeme, die auf anderen Dateidatenplattformen nicht verfügbar ist. Diese Analysen bieten Transparenz und Einblicke in die Leistungsauslastung jeder Workload (entweder nach Client oder nach Datenpfad) und in das Kapazitätswachstum ihres Systems, einschließlich einer Ansicht darüber, welche Teile der Dateidatenplattform nach Zeitraum wachsen oder schrumpfen, So können Kunden herausfinden, welche Workloads ihre Kapazität verbrauchen.
Teilen
In diesem Abschnitt können Administratoren Benutzern Daten zugänglich machen, indem sie SMB-Freigaben und NFS-Exporte erstellen. Außerdem können Administratoren die Kapazitätsauslastung über Kontingente verwalten. Im Freigabebereich schließlich verwalten Administratoren die Verbindung des Clusters zu AD- und LDAP-Identitätsdiensten.
Cluster
In diesem Abschnitt können Administratoren Snapshot-Richtlinien, Richtlinien für die kontinuierliche Replikation, Netzwerke sowie Zeit- und Datumsdienste konfigurieren. Es ermöglicht ihnen, die Knoten des Systems zu sehen und neue Knoten hinzuzufügen.
API & Tools
In diesem Abschnitt können Kunden das Qumulo-Befehlszeilentool herunterladen und unsere selbstdokumentierende API erkunden. Es beinhaltet die Möglichkeit, jeden Endpunkt zu „versuchen“ und JSON-Beispielausgaben anzuzeigen.
Support
In diesem Abschnitt können Kunden Software-Upgrades mit Qumulo Instant Upgrade durchführen, eine Verbindung zur Fernüberwachung herstellen und das Kundenerfolgsteam von Qumulo autorisieren, sich aus der Ferne mit einem Qumulo-System zu verbinden.
Innovationspunkte
Die Qumulo-API bietet eine vollständige Obermenge aller Funktionen der Qumulo-Dateidatenplattform, die es Kunden ermöglicht, mit der Software von Qumulo zu entwickeln und ihr Qumulo-System vollständig über moderne Infrastrukturverwaltungstools zu verwalten.
Die visuelle Benutzeroberfläche von Qumulo bietet einfache (und verständliche) Tools zur Verwaltung von Qumulo-Systemen, die den IT-Aufwand in Bezug auf Kosten und Zeit reduzieren.
Das Dashboard und die visuelle Analyseschnittstelle bieten umsetzbare Echtzeit-Einblicke in jede Qumulo-Dateidatenplattform. Benutzer können verstehen, wie gut ihre Qumulo-Dateidatenplattform den Erstellern dient und Einblicke in die Arbeitsbelastung dieser Ersteller bietet.
Datendienste
Zweck
Schützen, sichern und verwalten Sie Daten auf der Qumulo-Dateiplattform mit den Tools der Enterprise-Klasse, die CIOs und CSOs von Datenplattformen erwarten.
So funktioniert's
Die Data-Services-Schicht besteht aus fünf Funktionen – Snapshots, Replikation, Kontingente, Audit, rollenbasierte Zugriffskontrolle (RBAC) und Shift to Amazon S3.
Snapshots
Daten, die in einer Qumulo-Dateidatenplattform gespeichert sind, können sowohl in ihrer aktuellen Form als auch in früheren Versionen über Snapshots angezeigt werden. Diese Snapshots verwenden eine einzigartige Methode zum Versetzen des Platzes, die nur dann Speicherplatz verbraucht, wenn Änderungen auftreten. Dies macht die Snapshots von Qumulo sowohl effizient als auch performant. Snapshots werden durch eine Snapshot-Richtlinie gesteuert, die den zu schützenden Teil des Namespace, die Häufigkeit der Snapshots und die Aufbewahrungsdauer der Snapshots festlegt.
Snapshot-Richtlinien können mit Replikationsrichtlinien verknüpft werden. Dadurch können Snapshots auf eine zweite Qumulo-Dateidatenplattform repliziert und häufige Snapshots auf einer Qumulo-Dateidatenplattform und weniger häufige Snapshots auf einer anderen gespeichert werden (eine übliche Strategie zum Schutz von Unternehmensdaten vor Datenverlust und Ransomware). Administratoren können Snapshots wiederherstellen und einzelne Dateien können über die visuelle Schnittstelle/CLI/API oder direkt von Endbenutzern über Client-Tools (zB „Vorherige Versionen“ in Windows) wiederhergestellt werden. Das Limit für die Gesamtzahl von Snapshots in einer Qumulo-Dateidatenplattform liegt bei Zehntausenden und ist damit höher als bei den meisten anderen Systemen.
Replikation
Die Replikation ermöglicht es Benutzern, Daten über mehrere Qumulo-Dateidatenplattformen hinweg zu kopieren, zu verschieben und zu synchronisieren. Unsere Replikationstechnologie bietet zwei Kernfunktionen: effiziente Datenbewegung und granulare Identifizierung geänderter Daten. Die Replikation von Qumulo erfolgt kontinuierlich, was bedeutet, dass alle neuen Änderungen an einem replizierten Verzeichnis identifiziert und asynchron und unidirektional verschoben werden. Unsere Replikationstechnologie nutzt Snapshots, um eine Liste geänderter Dateibereiche in einem bestimmten Zeitraum zu erstellen, die dann über ein verschlüsseltes Datenübertragungsprotokoll auf eine zweite Qumulo-Dateidatenplattform verschoben werden. Die Liste der geänderten Dateien steht als eigener API-Endpunkt zur Verfügung, mit dem ISVs von Drittanbietern Qumulo in Datensicherungssysteme integrieren. Die Replikation von Qumulo funktioniert auf zwei beliebigen Qumulo-Dateidatenplattformen, einschließlich On-Prem-to-Cloud, Cloud-to-Cloud und über Cloud-Regionen hinweg. Die Replikation wird verwendet, um Backups im Petabyte-Bereich zu ermöglichen, insbesondere in Verbindung mit der Notfallwiederherstellung mit Snapshot-Replikation, einschließlich Failover und Failback. Es ermöglicht auch Hybrid-Cloud- und Cloud-Bursting-, Multi-Cloud- und Multi-Region-Infrastruktur sowie Remote-Zusammenarbeitsszenarien.
Qumulo Shift zu Amazon S3
Die Objektspeicherreplikation ermöglicht es jeder Qumulo-Dateidatenplattform, einen Cloud-Objektspeicherdienst (z. B. Amazon S3) als geeignetes Replikationsziel zu behandeln. Benutzer können Daten aus einem Qumulo-Namespace über Qumulo Shift einmalig oder kontinuierlich in einen Cloud-Objektspeicher kopieren und umgekehrt. In einen Objektspeicher verschobene Daten werden in einem offenen und nicht proprietären Format gespeichert, sodass Entwickler diese Daten über Anwendungen nutzen können, die direkt mit dem Amazon S3-Cloud-Objektspeicher im nativen Amazon S3-Format verbunden sind. Beispielszenarien umfassen die Archivierung von Daten aus einem Qumulo-Namespace in Amazon S3-Cloud-Objekt-Cold-Storage-Tiers oder die Aktivierung von datenbasierten Machine-Learning-Diensten von Amazon S3, um Daten zu verarbeiten, die auf einer Qumulo-Dateidatenplattform erfasst und bearbeitet wurden.
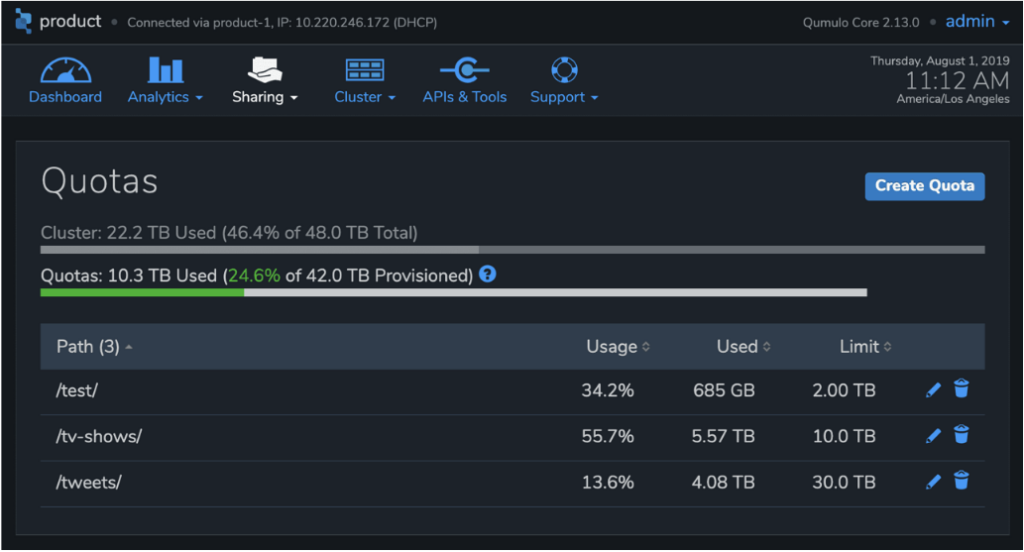
Quoten
Mit Kontingenten können Benutzer das Wachstum jeder Teilmenge eines Qumulo-Namespace steuern. Kontingente fungieren als unabhängige Grenzen für die Größe jedes Verzeichnisses und verhindern ein Datenwachstum, wenn die Kapazitätsgrenze erreicht ist. Im Gegensatz zu anderen Produkten werden Qumulo-Kontingente sofort wirksam, sodass Administratoren mithilfe unserer Echtzeit-Kapazitätsanalyse unerwünschte Arbeitslasten identifizieren und eine übermäßige Kapazitätsauslastung sofort stoppen können. Kontingente folgen sogar dem Teil des Namespace, den sie abdecken, wenn Verzeichnisse verschoben oder umbenannt werden.
Audit
Audit ermöglicht es Sicherheitsadministratoren, alle in einem Qumulo-Namespace durchgeführten Aktionen und Konfigurationsänderungen am System zu verfolgen. Audit erfasst alle Datenzugriffe und -änderungen, Versuche, auf eine Qumulo-Dateidatenplattform zuzugreifen, die gemeinsame Nutzung von Daten durch neue Freigaben oder Exporte sowie Änderungen an der Systemkonfiguration oder an Datenschutzschemata. Audit sendet diese Aktivitätsprotokolle an einen beliebigen Standard-Remote-Syslog-Server.
Rollenbasierte Zugriffssteuerung
Mit der rollenbasierten Zugriffskontrolle (RBAC) können Sicherheitsadministratoren ihre Identitätsdienste verwenden, um zu steuern, welche Benutzer oder Gruppen Rechte haben, um Änderungen an einer Qumulo-Dateidatenplattform vorzunehmen oder die visuelle Benutzeroberfläche anzuzeigen. RBAC bietet mehrere vorkonfigurierte „Rollen“, die Rechte zum Handeln im oder am System haben (Admin, Observer, Data Admin). Administratoren fügen diesen Rollen Benutzer und Gruppen aus AD oder LDAP hinzu. Administratoren können auch benutzerdefinierte Rollen erstellen, die den einzigartigen Sicherheitssystemen in ihrer Organisation entsprechen (z. B. eine „Backup-Administrator“-Rolle).
Innovationspunkte
Qumulo Shift kopiert Daten aus einer Datei in das native Amazon A3-Objektformat, sodass die Daten problemlos von nativen AWS-Cloud-Services verwendet werden können.
Snapshots in der Dateidatenplattform von Qumulo sind effizient, leistungsstark und skalierbar (bis 40k oder mehr).
Die Snapshot-Replikation ermöglicht ein integriertes Backup im Petabyte-Bereich für jede Qumulo-Dateidatenplattform, unabhängig davon, wo sie sich befindet.
Die Replikation ermöglicht jeder Qumulo-Dateidatenplattform das Kopieren, Verschieben oder Synchronisieren von Daten mit jeder anderen Qumulo-Dateidatenplattform (von lokal in die Cloud, von Cloud-Region zu Cloud-Region oder über Clouds hinweg).
Kontingente in Qumulo erfolgen in Echtzeit und erfordern keine langwierigen Aufzählungen der Datenplattform (auch bekannt als „Tree Walks“), um wirksam zu werden.
Audit lässt sich einfach in moderne Infrastrukturverwaltungstools wie Splunk integrieren.
Das Qumulo-Dateisystem
Zweck
Organisieren Sie Daten in verständlichen Strukturen, ermöglichen Sie Workloads mit enormen Dateizahlen, ermöglichen Sie es Erstellern, an Datensätzen zusammenzuarbeiten, während sie sich durch den Datenlebenszyklus bewegen, und bieten Sie Echtzeiteinblicke in Leistung und Kapazitätsauslastung, selbst wenn Systeme auf Petabytes und Milliarden von Dateien skaliert werden .
So funktioniert's
Das Qumulo-Dateisystem organisiert alle in einem Qumulo-System gespeicherten Daten in einem Namensraum. Dieser Namespace ist POSIX-kompatibel und verwaltet die Berechtigungen und Identitätsinformationen, die die vollständige Semantik unterstützen, die über die NFS- oder SMB-Protokolle verfügbar ist. Wie alle Dateidatenplattformen organisiert die Qumulo-Dateidatenplattform Daten in Verzeichnissen und präsentiert Daten für SMB- und NFS-Clients. Die Dateidatenplattform von Qumulo hat jedoch mehrere einzigartige Eigenschaften: die Verwendung von B-Trees, einer Echtzeit-Analyse-Engine und Cross-Protocol-Berechtigungen (XPP).
B-Trees in der File Data Platform
Die Qumulo-Dateidatenplattform kann auf Milliarden von Dateien skaliert werden, ohne dass die bei anderen Plattformen üblichen Probleme auftreten, wie z. Dies erreichen wir durch den Einsatz einer Reihe von Technologien, von denen eine der B-Baum ist. B-Bäume eignen sich besonders gut für Systeme, die eine große Anzahl von Datenblöcken lesen und schreiben, da es sich um „flache“ Datenstrukturen handelt, die bei steigender Datenmenge die für jede Operation erforderliche E/A-Menge minimieren. Mit B-Trees als Grundlage wächst der Rechenaufwand für das Lesen oder Einfügen von Datenblöcken mit zunehmender Datenmenge sehr langsam.
B-Trees sind beispielsweise ideal für Dateidatenplattformen und sehr große Datenbankindizes. In der Dateidatenplattform von Qumulo sind B-Bäume blockbasiert. Jeder Block ist 4096 Byte groß, und jeder 4K-Block kann Zeiger auf andere 4K-Blöcke haben. Die Dateidatenplattform Qumulo verwendet B-Trees für viele verschiedene Zwecke. Es gibt einen Inode-B-Baum, der als Index aller Dateien dient. Die Inode-Liste ist eine Standardimplementierungstechnik für Dateidatenplattformen, die das Prüfen der Konsistenz der Dateidatenplattform unabhängig von der Verzeichnishierarchie macht. Inodes helfen auch dabei, Aktualisierungsvorgänge wie Verzeichnisverschiebungen effizient zu gestalten. Dateien und Verzeichnisse werden als B-Bäume mit eigenen Schlüssel/Wert-Paaren dargestellt, wie beispielsweise dem Dateinamen, seiner Größe und seiner Zugriffskontrollliste (ACL) oder POSIX-Berechtigungen. Konfigurationsdaten sind ebenfalls ein B-Baum und enthalten Informationen wie die IP-Adresse des Clusters.
Echtzeit-Analyse-Engine
Qumulo bietet Einblicke in die Kapazitäts- und Leistungsnutzung von Daten in einer Qumulo-Dateidatenplattform. Dadurch können Kunden fast sofort sehen, welche Teile der Dateidatenplattform gewachsen (oder geschrumpft) sind, welche Anwendungen Leistungsressourcen verbrauchen und welche Teile der Dateidatenplattform am aktivsten sind. Auf diese Weise können Kunden Fehler in Anwendungen beheben, den Kapazitätsverbrauch verwalten und mit echten Daten planen. Diese Erkenntnisse werden durch zwei Technologien unterstützt: Kapazitätsmetadatenaggregation und Dateidatenplattform-Sampling.
Aggregation von Kapazitätsmetadaten
In der Qumulo-Dateidatenplattform werden Metadaten wie verwendete Bytes und Dateianzahlen als Dateien aggregiert und Verzeichnisse erstellt oder geändert. Dies bedeutet, dass die Informationen für eine zeitnahe Verarbeitung ohne teure Dateidatenplattform-Treewalks zur Verfügung stehen. Die Echtzeit-Analyse-Engine verwaltet aktuelle Metadatenzusammenfassungen im gesamten Dateidatenplattform-Namespace. Es verwendet die B-Bäume der Dateidatenplattform, um Informationen über die Dateidatenplattform zu sammeln, wenn Änderungen auftreten. Innerhalb der Dateidatenplattform werden verschiedene Metadatenfelder zusammengefasst, um einen virtuellen Index zu erstellen. Wenn Änderungen auftreten, werden neue aggregierte Metadaten gesammelt und Änderungen werden von den einzelnen Dateien an den Stamm der Dateidatenplattform weitergegeben.
Wenn jede Datei (oder jedes Verzeichnis) mit neuen aggregierten Metadaten aktualisiert wird, wird ihr übergeordnetes Verzeichnis als veraltet markiert und ein weiteres Aktualisierungsereignis wird für das übergeordnete Verzeichnis in die Warteschlange gestellt. Auf diese Weise werden Dateidatenplattforminformationen gesammelt und aggregiert, während sie den Baum hochgereicht werden. Die Metadaten breiten sich beim Zugriff auf die Daten vom einzelnen Knoten auf der untersten Ebene nach oben zum Stamm der Dateidatenplattform aus. Jede Datei- und Verzeichnisoperation wird berücksichtigt.
Parallel zur Bottom-up-Propagierung von Metadatenereignissen beginnt ein periodischer Durchlauf am oberen Rand der Dateidatenplattform und liest die in den Metadaten enthaltenen aggregierten Informationen. Wenn die Traversierung kürzlich aktualisierte aggregierte Informationen findet, beschneidet sie ihre Suche und geht zum nächsten Zweig über. Es wird davon ausgegangen, dass aggregierte Informationen im Dateidatenplattformbaum von diesem Punkt bis zu den Blättern einschließlich aller enthaltenen Dateien und Verzeichnisse aktuell sind und für zusätzliche Analysen nicht tiefer gehen müssen. Der Großteil der Metadatenzusammenfassung wurde bereits berechnet, und im Idealfall muss die Durchquerung nur eine kleine Teilmenge der Metadaten für die gesamte Dateidatenplattform zusammenfassen. Tatsächlich treffen sich die beiden Teile des Aggregationsprozesses in der Mitte, ohne dass man den gesamten Dateidatenplattformbaum von oben nach unten durchsuchen muss.
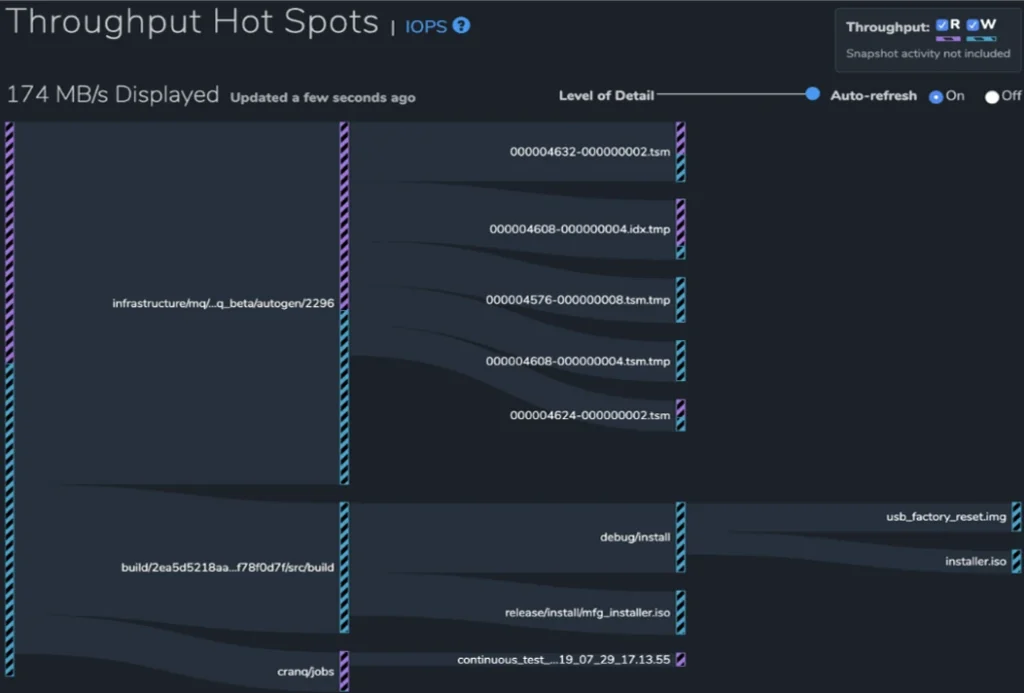
Dateisystem-Sampling
Ein Beispiel für die Echtzeitanalysen von Qumulo sind die Leistungs-Hotspot-Berichte. Die Darstellung aller Durchsatzoperationen und IOPS innerhalb der visuellen Schnittstelle wäre bei großen Dateidatenplattformen nicht machbar. Stattdessen verwendet die Echtzeit-Analyse-Engine von Qumulo probabilistisches Sampling, um eine statistisch gültige Annäherung dieser Informationen bereitzustellen. Summen für IOPS-Lese- und -Schreibvorgänge sowie für E/A-Durchsatz-Lese- und -Schreibvorgänge werden aus Stichproben generiert, die aus einem In-Memory-Puffer von Zehntausenden oder mehr Einträgen gesammelt werden, die alle paar Sekunden aktualisiert werden.
Der angezeigte Bericht zeigt die Vorgänge an, die die größten Auswirkungen auf den Cluster haben. Diese werden in der visuellen Oberfläche als Hotspots dargestellt.
Die Fähigkeit von Qumulo, statistisch gültiges probabilistisches Sampling zu verwenden, ist nur aufgrund der zusammengefassten Metadaten für jedes Verzeichnis (verwendete Bytes, Dateianzahl) möglich, die von der Echtzeit-Analyse-Engine ständig auf dem neuesten Stand gehalten werden.
Protokollübergreifende Berechtigungen (XPP)
Um Entwicklern zu ermöglichen, Daten über den gesamten Innovationslebenszyklus hinweg auszutauschen, muss Qumulo den Zugriff auf dieselben Daten durch eine Vielzahl von Betriebssystemen (z. B. Windows, Mac, Linux) ermöglichen. Diese Systeme verlassen sich jedoch auf NFS und SMB, die sehr unterschiedliche Sprachen haben, um Identität auszudrücken. Als Beispiel könnte ein Labor Daten mit einem genomischen Sequenzer erstellen, auf dem Windows ausgeführt wird, und daher die Identität mit der reichhaltigen Sprache von ACEs und ACLs ausdrücken. Dann könnte ein Forscher diese Daten mit einem Windows-Client analysieren, der ebenfalls SMB verwendet und daher ACLs versteht. Irgendwann wird der Forscher eine parallele Rechenoperation mit einem HPC-Cluster unter Linux koordinieren wollen, der POSIX-Berechtigungen (zB Modusbits) erwartet. Die Forschungsorganisation stünde vor der Wahl, entweder alle Berechtigungen auf den am wenigsten restriktiven Satz zu vereinfachen und so den erforderlichen Zugriff zu ermöglichen, oder die Daten in einen völlig separaten Namensraum zu verschieben, was den Zusammenarbeitsfluss unterbrechen und die IT-Kosten erhöhen würde.
Qumulo löste dieses Problem durch die Schaffung einer Dateidatenplattform, die mehrere Berechtigungssprachen übersetzen und rationalisieren kann, sodass jeder Client die erwarteten Berechtigungen sieht, ohne die Protokollausdrücklichkeit zu beeinträchtigen. Wir nennen diese Technologie XPP. Cross-Protocol Permissions (XPP) ermöglicht gemischte SMB- und NFS-Protokoll-Workflows durch Beibehaltung von SMB-ACLs, Beibehaltung der Berechtigungsvererbung und Reduzierung von Anwendungsinkompatibilitäten in Bezug auf Berechtigungseinstellungen.
Cross-Protocol Permissions ist für den Betrieb auf folgende Weise ausgelegt:
- Wenn keine protokollübergreifende Interaktion stattfindet, arbeitet Qumulo genau nach Protokollspezifikationen.
- Wenn Konflikte zwischen Protokollen auftreten, minimieren protokollübergreifende Berechtigungen die Wahrscheinlichkeit von Anwendungsinkompatibilitäten.
- Durch das Aktivieren protokollübergreifender Berechtigungen werden die Rechte an vorhandenen Dateien in einem Dateisystem nicht geändert. Änderungen können nur vorgenommen werden, wenn Dateien geändert werden, während der Modus aktiviert ist.
Innovationspunkte
Die Dateidatenplattform von Qumulo kann auf Milliarden von Dateien skaliert werden, während hohe Effizienz, Ausfallsicherheit bei Komponentenausfällen und hohe Leistung erhalten bleiben.
Kunden können Workflows diagnostizieren, fehlerhafte Anwendungen identifizieren, den Kapazitätsverbrauch verwalten und für die Zukunft planen, indem sie Echtzeitdaten zu Leistung und Kapazitätsauslastung verwenden, selbst in milliardenschweren Datei- und Petabyte-großen Dateidatenplattformen.
Ersteller können über den gesamten Datenlebenszyklus hinweg zusammenarbeiten, indem sie Standardtools für Endbenutzer-Clients und HPC-Computing verwenden, und zwar über denselben Qumulo-Namespace dank protokollübergreifender Berechtigungen.
Die Dateidatenplattform von Qumulo kann auf Milliarden von Dateien skaliert werden, während hohe Effizienz, Ausfallsicherheit bei Komponentenausfällen und hohe Leistung erhalten bleiben.
Kunden können Workflows diagnostizieren, fehlerhafte Anwendungen identifizieren, den Kapazitätsverbrauch verwalten und für die Zukunft planen, indem sie Echtzeitdaten zu Leistung und Kapazitätsauslastung verwenden, selbst in milliardenschweren Datei- und Petabyte-großen Dateidatenplattformen.
Ersteller können über den gesamten Datenlebenszyklus hinweg zusammenarbeiten, indem sie Standardtools für Endbenutzer-Clients und HPC-Computing verwenden, und zwar über denselben Qumulo-Namespace dank protokollübergreifender Berechtigungen.
Der skalierbare Blockspeicher
Zweck
Bringen Sie die Qumulo-Dateidatenplattform in jede private und öffentliche Cloud-Umgebung, ermöglichen Sie eine massive Skalierung, garantieren Sie die Konsistenz im gesamten System, schützen Sie sich vor Komponentenausfällen und ermöglichen Sie hohe Leistung und interaktive Workloads.
So funktioniert's
Die Grundlage der Qumulo-Dateidatenplattform ist der Scalable Block Store (SBS). Der SBS nutzt mehrere Kerntechnologien, um Skalierbarkeit, Portabilität, Schutz und Leistung zu ermöglichen: ein virtualisiertes Blocksystem, Löschcodierung, ein globales Transaktionssystem und ein intelligenter Cache.
Das virtuelle Blocksystem
Die Speicherkapazität eines Qumulo-Systems ist konzeptionell in einem einzigen, geschützten virtuellen Adressraum organisiert. Jede geschützte Adresse in diesem Bereich speichert einen 4K-Byteblock. Jeder dieser „Blöcke“ wird durch ein Löschcodierungsschema geschützt, um Redundanz bei einem Ausfall des Speichergeräts zu gewährleisten. Die gesamte Dateidatenplattform wird innerhalb des von SBS bereitgestellten geschützten virtuellen Adressraums gespeichert, einschließlich der Verzeichnisstruktur, Benutzerdaten, Dateimetadaten, Analyse- und Konfigurationsinformationen.
Der geschützte Speicher fungiert als Schnittstelle zwischen der Dateidatenplattform und den blockbasierten Daten, die auf den angeschlossenen Blockgeräten aufgezeichnet werden. Bei diesen Geräten kann es sich um Flash-Geräte oder Festplatten handeln, entweder auf einem dedizierten Server in der privaten Cloud oder auf einem virtuellen Server in der öffentlichen Cloud. Durch die Verwendung von 4K-Blöcken ermöglicht das virtuelle Blocksystem eine hocheffiziente Speicherung aller Dateigrößen (groß bis klein).
Löschcodierung
Jeder virtuelle Block ist Teil einer größeren Schutzgruppe namens Protected Store (oder Pstore), die Löschcodierung nutzt, um Daten über eine verteilte Qumulo-Dateidatenplattform zu verteilen und zu schützen. Dieser pstore ist der organisierende Container für den Datenschutz. Innerhalb und zwischen pstores nutzen Datenblöcke Reed-Solomon-Algorithmen, um „Paritätskopien“ von Datenblöcken zu erstellen, die verwendet werden, um Blöcke wieder aufzubauen, die durch einen Komponentenfehler beschädigt wurden. Die Anzahl der Paritätsblöcke bestimmt die Redundanz des Clusters, wobei größere Cluster mehr Redundanz erfordern als kleinere, da sie mehr Komponenten enthalten, die ausfallen könnten. Diese Pstores werden dann über eine Qumulo-Dateidatenplattform verteilt, um Komponentenfehler in einem virtuellen oder physischen Server mit CPU, Speichergeräten und Netzwerk zu kontrollieren.
Die Implementierung von Erasure Coding von Qumulo in Verbindung mit unserem granularen virtuellen Adressraum ermöglicht es der Qumulo-Dateidatenplattform, Daten aus ausgefallenen Komponenten schnell und vorhersehbar neu zu erstellen. Darüber hinaus können die Systeme die dichtesten Flash- und Disk-basierten Medien nutzen, die in der Public und Private Cloud verfügbar sind, und große Systeme mit zuverlässiger Leistung und starken Datenschutzgarantien betreiben. Schließlich ermöglicht dieses Schutzsystem den Kunden, 100 % des verfügbaren geschützten Speicherplatzes in einem Qumulo-System sicher zu nutzen, im Gegensatz zu anderen Systemen, die über ~80 % Auslastung hinaus schlecht oder unvorhersehbar funktionieren.
Der geschützte Speicher fungiert als Schnittstelle zwischen der Dateidatenplattform und den blockbasierten Daten, die auf den angeschlossenen Blockgeräten aufgezeichnet werden. Bei diesen Geräten kann es sich um Flash-Geräte oder Festplatten handeln, entweder auf einem dedizierten Server in der privaten Cloud oder auf einem virtuellen Server in der öffentlichen Cloud. Durch die Verwendung von 4K-Blöcken ermöglicht das virtuelle Blocksystem eine hocheffiziente Speicherung aller Dateigrößen (groß bis klein).
Globales Transaktionssystem
Da Qumulo eine verteilte Shared-Nothing-Dateidatenplattform ist, die sofortige Konsistenzgarantien bietet, benötigen wir einen Mechanismus, um sicherzustellen, dass jeder Knoten im System eine konsistente Ansicht aller Daten hat. Wir erreichen dies, indem wir sicherstellen, dass alle Lese- und Schreibvorgänge in den virtuellen Adressraum transaktional sind.
Dies bedeutet, dass, wenn eine Dateidatenplattformoperation eine Schreiboperation erfordert, die mehr als einen Block umfasst, die Operation entweder alle relevanten Blöcke oder keinen von ihnen schreibt. Atomare Lese- und Schreiboperationen sind für die Datenkonsistenz und die korrekte Implementierung von Dateiprotokollen wie SMB und NFS unerlässlich. Für eine optimale Leistung verwendet SBS Techniken, die Parallelität und verteiltes Rechnen maximieren und gleichzeitig die Transaktionskonsistenz der E/A-Operationen aufrechterhalten. SBS wurde beispielsweise entwickelt, um serielle Engpässe zu vermeiden, bei denen Operationen in einer Reihenfolge statt parallel ausgeführt würden. Das Transaktionssystem von SBS verwendet Prinzipien des ARIES-Algorithmus, der üblicherweise in Datenbanken für nicht blockierende Transaktionen verwendet wird, einschließlich Write-Ahead-Protokollierung, Wiederholung des Verlaufs während „Rückgängig“-Aktionen und Protokollierung von „Rückgängig“-Aktionen.
Die Umsetzung von Transaktionen durch SBS weist jedoch einige wichtige Unterschiede zu ARIES auf. SBS nutzt die Tatsache, dass Transaktionen, die von der Qumulo-Dateidatenplattform initiiert werden, vorhersehbar kurz sind, im Gegensatz zu Universaldatenbanken, bei denen Transaktionen langlebig sein können. Ein Nutzungsmuster mit kurzlebigen Transaktionen ermöglicht es SBS, das Transaktionsprotokoll aus Effizienzgründen häufig zu trimmen. Kurzlebige Transaktionen ermöglichen eine schnellere Auftragsbestellung.
Darüber hinaus sind die Transaktionen von SBS stark verteilt und erfordern keine global definierte Gesamtordnung von Sequenznummern im ARIES-Stil für jeden Transaktionsprotokolleintrag. Stattdessen sind Transaktionsprotokolle in jedem der virtuellen Blöcke lokal sequentiell und auf globaler Ebene koordiniert, wobei ein teilweises Ordnungsschema verwendet wird, das Beschränkungen bei der Reihenfolge der Verpflichtungen berücksichtigt.
Der Vorteil des SBS-Ansatzes besteht darin, dass für transaktionale I/O-Operationen nur ein Minimum an Sperren verwendet wird, wodurch Qumulo-Cluster auf viele Hundert Knoten skaliert werden können.
Intelligentes Caching und Prefetching
Die Dateidatenplattform Qumulo speichert Milliarden von Dateien und eine Kapazität von mehreren Petabyte. Zu einem bestimmten Zeitpunkt befindet sich jedoch nur ein kleiner Teil dieser Daten im aktiven Arbeitssatz eines Schöpfers oder Innovators. Um sicherzustellen, dass diese Ersteller die schnellstmögliche Leistung haben, und um zu verhindern, dass Kunden für jede Phase des Datenlebenszyklus unterschiedliche Systeme kaufen, gibt Qumulo in unserem Produkt mehrere Leistungsgarantien:
1. Alle Metadaten, die in jedem Datensatz am häufigsten gelesen werden, befinden sich auf dem schnellsten dauerhaften Medium im System (z. B. Flash).
2. Virtuelle Blöcke, die häufig gelesen werden (gemessen durch einen proprietären „Wärmeindex“), werden auf Flash gespeichert, virtuelle Blöcke, die selten gelesen werden, werden auf kältere Medien verschoben, sofern verfügbar.
3. Beim Lesen von Daten beobachtet das System das Verhalten des Clients und ruft neue Daten auf intelligente Weise vorab in den Speicher des Knotens ab, der dem Client am nächsten liegt, um die Zugriffszeiten zu beschleunigen. Dies erreichen wir durch die intelligente Anwendung einer Reihe von Vorhersagemodellen, die Datenbenennungsschemata, Datengeburtsreihenfolge und Lesemuster in großen Dateien beobachten. Das System nutzt auf intelligente Weise das effektivste Modell für jede Arbeitslast und schaltet verschwenderische Modelle aus.
Verschlüsselung in Ruhe
Qumulo verschlüsselt automatisch alle Systeme auf Schutzsystemebene mit der branchenüblichen AES256-Verschlüsselung im XTS-Modus. Mit dieser Methode werden alle Qumulo-Dateidatenplattformen vor Angriffen auf die zugrunde liegenden Komponenten geschützt. Das System präsentiert einen einzigen Hauptschlüssel, der auf mehreren Datenschlüsseln sitzt und vom Kunden gedreht werden kann. Durch die Kombination dieser softwarebasierten Verschlüsselung mit Identitätsmanagement, RBAC, Audit und Verschlüsselung von SMB- und Replikationsverkehr können Kunden die strengen Sicherheitsanforderungen des Unternehmens erfüllen.
Sofortiges Upgrade
Qumulo ist ein agiles Softwareentwicklungsunternehmen und daher veröffentlichen wir regelmäßig neue Verbesserungen. Wir möchten, dass unsere Kunden schnell und einfach auf diese neuen Erweiterungen zugreifen können.
Qumulo hat den Qumulo Core-Upgrade-Prozess so konzipiert, dass er schnell und einfach ist. Qumulo Core ist containerisiert, was es uns ermöglicht, einen gesamten Cluster unabhängig von der Größe in 20 Sekunden zu aktualisieren. Indem wir einen sekundären Qumulo Core aufstellen, eliminieren wir Rollbacks, da die Funktionalität und Stabilität des Qumulo Core demonstriert werden kann, bevor ein Upgrade stattfindet.
Dynamische Skala
Qumulo ist der Meinung, dass Ihnen der Zugriff auf die neueste Technologie nicht vorenthalten werden sollte. Daten wachsen schnell und Sie benötigen Zugriff auf neue Technologien, um Schritt zu halten. Legacy-Anbieter können mit der Softwareunterstützung für neue Hardwareinnovationen nicht Schritt halten. Diese Anbieter benötigen häufig Gabelstapler-Upgrades, die eine zeitintensive und komplexe Datenmigration erfordern und/oder komplexe Speicherpools erstellen, die schwer zu verwalten sind.
Qumulo bietet eine dynamische Skalierung mit Knotenkompatibilität, die es Ihnen ermöglicht, neue Prozessoren, Speicher und Arbeitsspeicher in bestehenden Bereitstellungen zu nutzen. Diese Knotenkompatibilität ermöglicht es Kunden, ihre Cluster weiterhin problemlos mit neueren Systemgenerationen zu erweitern. Alle Qumulo-Systeme werden einen Weg zur Erweiterung auf neue Generationen von Hardware und eine dichtere Konfiguration haben.
Innovationspunkte
Der Qumulo SBS abstrahiert die zugrunde liegenden Hardwarekomponenten, sodass die Qumulo-Dateidatenplattform in öffentlichen und privaten Cloud-Umgebungen ausgeführt werden kann.
Der SBS von Qumulo bietet eine einzigartig effiziente Speicherung über alle Dateigrößen hinweg.
Die Kombination aus einem virtualisierten Blocksystem und Erasure Coding ermöglicht es Kunden, ihren gesamten verfügbaren Speicherplatz zu nutzen und die dichtesten Speichergeräte zu nutzen, die in der privaten und öffentlichen Cloud angeboten werden.
Qumulo SBS ermöglicht Kunden den komfortablen Aufbau sehr großer Systeme. Unser Limit ab März 2020 beträgt 100 Knoten und 36 PB in einem Namespace, obwohl die Erhöhung dieses Limits eine Funktion des Tests und nicht der Architektur ist.
Das globale Transaktionssystem von Qumulo ermöglicht eine massiv skalierbare Leistung mit hocheffizienter verteilter Sperrung, um sofortige Konsistenz zu gewährleisten.
Das prädiktive Caching und Prefetching von Qumulo für maschinelles Lernen ermöglicht eine hohe Leistung bei den aktivsten Daten und ermöglicht gleichzeitig eine Skalierung der Systeme, die groß genug ist, um den gesamten Innovationsdatenlebenszyklus zu bedienen.
Qumulo Instant Upgrade ermöglicht das Upgrade von Clustern jeder Größe in 20 Sekunden, wodurch die Vorplanung und ständige Überwachung der meisten Infrastruktur-Upgrades entfällt.
Zusammenfassung
Qumulo hat eine Dateidatenplattform entwickelt, die den gesamten Datenlebenszyklus von der Erfassung über die Transformation bis hin zur Archivierung in der privaten und öffentlichen Cloud abdecken kann. Um dies zu erreichen, bietet Qumulo ein Cloud-fähiges, skalierbares und benutzerfreundliches System. ermöglicht Entwicklern die Verwendung von Standardtools, bietet Automatisierungsfunktionen und Transparenz und ist sicher und unternehmenstauglich.
Cloud-fähig
Die Qumulo-Dateidatenplattform ist sowohl in der öffentlichen, privaten als auch in der hybriden Cloud verfügbar.
Skalieren
Die Dateidatenplattform Qumulo lässt sich sicher auf Milliarden von Dateien und Petabyte an Daten skalieren. Die Qumulo-Dateidatenplattform lässt sich auch in der Leistung skalieren, um die Anforderungen der anspruchsvollsten Workloads zu erfüllen.
Standardwerkzeuge
Die Qumulo-Dateidatenplattform unterstützt Windows-, Mac- und Linux-Clients.
Automatisierung und Sichtbarkeit
Die Dateidatenplattform Qumulo bietet eine robuste API für Programmierbarkeit und Automatisierung sowie Echtzeiteinblicke in die Kapazitäts- und Leistungsauslastung des Systems.
Sicher und unternehmenstauglich
Die Dateidatenplattform Qumulo bietet die Identitäts-, Kontroll-, Verwaltungs- und Verschlüsselungstools, die Unternehmen von ihrer Infrastruktur benötigen.
Erleben Sie Qumulo live! (Demo-Session)
Überzeugen Sie sich selbst: mit Qumulo ist es kinderleicht, Ihre Dateidaten im Massive-Scale Bereich in hybriden Cloud-Umgebungen zu verwalten.